
En observant les modèles de pointe actuels, on constate qu’une grande majorité d’entre eux repose sur une architecture de modèle « mixture of experts » (MoE) qui imite l’efficacité du cerveau humain.
Tout comme le cerveau active des régions spécifiques en fonction de la tâche à accomplir, les modèles MoE répartissent le travail entre des « experts » spécialisés, n’activant que ceux qui sont pertinents pour chaque token IA. Il en résulte une génération plus rapide et plus efficace sans augmentation proportionnelle de la puissance de calcul.
Les acteurs du secteur partagent ce constat. Les 10 modèles open source les plus intelligents figurant dans le classement indépendant Artificial Analysis, utilisent une architecture MoE, y compris l’IA DeepSeek-R1 de DeepSeek, Kimi K2 Thinking de Moonshot,, gpt-oss-120B d’OpenAI et Mistral Large 3 de Mistral.
Cependant, il est notoirement difficile de faire évoluer les modèles MoE en production tout en offrant des performances élevées. Le codesign des systèmes GB200 NVL72 combine des optimisations matérielles et logicielles pour des performances et une efficacité maximales, et rend le déploiement à grande échelle des MoE simple et effectif.
Le modèle MoE Kimi K2 Thinking – listé comme le modèle open source le plus intelligent dans le classement Artificial Analysis – affiche des performances sur le système NVIDIA GB200 NVL72 10 fois supérieures à celles obtenues sur le NVIDIA HGX H200. S’appuyant sur les performances offertes par les modèles MoE DeepSeek-R1 et Mistral Large 3, cette avancée majeure explique pourquoi le MoE devient progressivement l’architecture la plus adoptée par les modèles de pointe, et pourquoi la plateforme d’inférence full-stack de NVIDIA est la clé pour en libérer tout le potentiel.
Qu’est-ce que le MoE, et pourquoi est-il devenu la norme pour les modèles de pointe ?
Jusqu’à présent, la norme du secteur pour créer une IA plus intelligente consistait simplement à construire des modèles plus grands et plus denses qui utilisaient tous leurs paramètres (souvent des centaines de milliards pour les modèles les plus performants d’aujourd’hui) afin de générer chaque token. Bien que puissante, cette approche nécessite une puissance de calcul et une énergie considérables, ce qui rend son déploiement à grande échelle difficile.
Tout comme le cerveau humain s’appuie sur des régions spécifiques pour traiter différentes tâches cognitives, qu’il s’agisse de traiter le langage, de reconnaître un visage ou de résoudre un problème mathématique, les modèles MoE comprennent plusieurs « experts » spécialisés. Pour un token donné, seuls les plus pertinents sont activés par un routeur. Grâce à cette conception, même si le modèle global peut contenir des centaines de milliards de paramètres, la génération d’un token ne nécessite que l’utilisation d’un petit sous-ensemble, souvent seulement quelques dizaines de milliards.
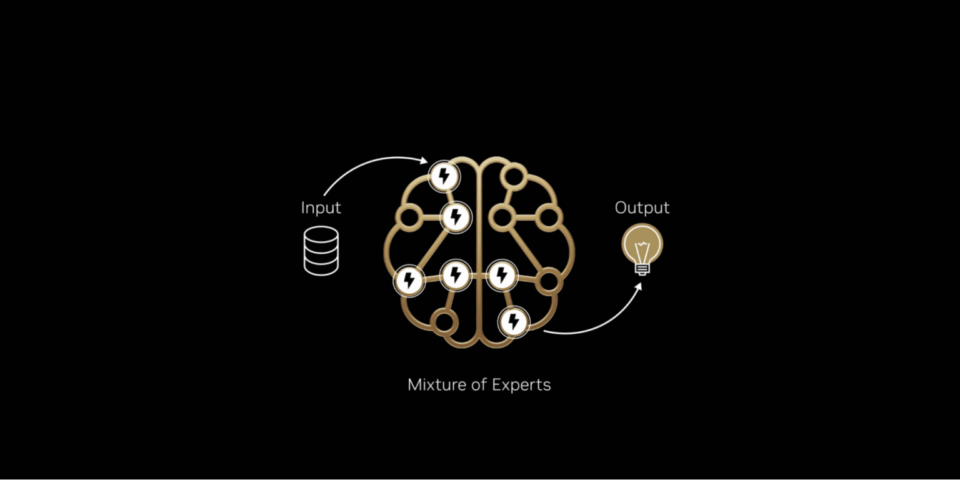
Tout comme le cerveau humain s’appuie sur des régions spécifiques pour traiter différentes tâches, les modèles MoE n’activent que les experts les plus pertinents via un routeur afin de générer chaque token.
En ne faisant appel qu’aux experts les plus importants, les modèles MoE atteignent un niveau d’intelligence et d’adaptabilité plus élevé sans augmentation proportionnelle du coût de calcul. Cela en fait la base de systèmes d’IA efficaces, optimisés en termes de performance par dollar et par watt, générant ainsi beaucoup plus d’intelligence pour chaque unité d’énergie et de capital investies.
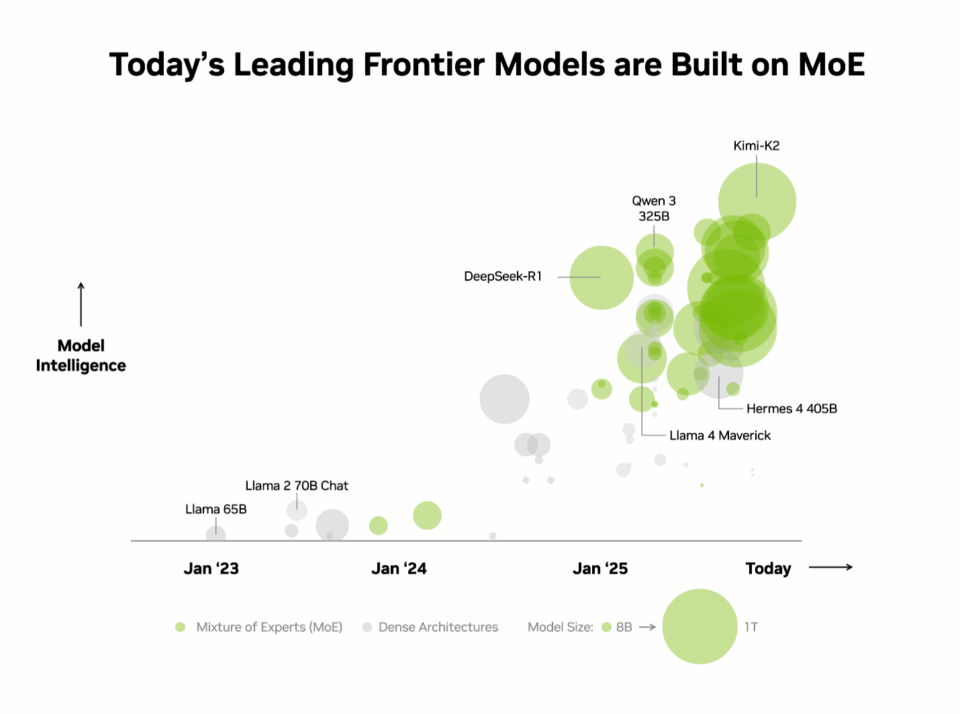
Compte tenu de ces avantages, il n’est pas surprenant que le MoE soit rapidement devenu l’architecture de choix pour les modèles de pointe, adoptée par plus de 60 % des modèles d’IA open source publiés cette année. Depuis début 2023, elle a permis de multiplier par 70 l’intelligence des modèles, repoussant ainsi les limites des capacités de l’IA.
« Notre travail pionnier avec les MoE open source, commencé il y a deux ans avec Mistral 8x7B, garantit que l’intelligence avancée est à la fois accessible et durable pour un large éventail d’applications », a déclaré Guillaume Lample, co-fondateur et chief scientist chez Mistral AI.« L’architecture MoE de Mistral Large 3 nous permet d’améliorer les performances et l’efficacité des systèmes d’IA tout en réduisant considérablement les besoins en énergie et en calcul »
Surmonter les goulots d’étranglement liés à la mise à l’échelle des modèles MoE grâce au codesign
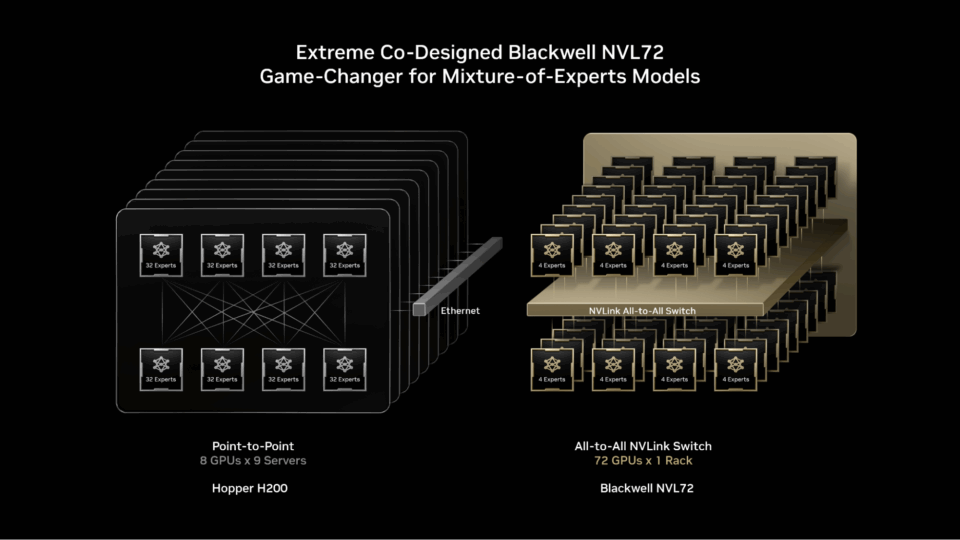
Les modèles MoE de pointe sont tout simplement trop volumineux et trop complexes pour être déployés sur un seul GPU. Pour les exécuter, les experts doivent être répartis sur plusieurs GPU, une technique appelée « parallélisme d’expert ». Même sur des plateformes puissantes telles que la NVIDIA H200, des goulots d’étranglement lors du déploiement de modèles MoE existent, comme par exemple :
- les limitations de mémoire : pour chaque token, les GPU doivent charger dynamiquement les paramètres des experts sélectionnés à partir d’une mémoire à bande passante élevée, ce qui entraîne une pression fréquente et importante sur la bande passante mémoire.
- la latence : les experts doivent exécuter un modèle de communication quasi instantané de type « all-to-all » pour échanger des informations et former une réponse finale complète. Cependant, sur H200, répartir les experts sur plus de huit GPU les oblige à communiquer via un réseau à haute latence, ce qui limite les avantages du parallélisme d’expert.
La solution : le codesign
NVIDIA GB200 NVL72 est un système à l’échelle d’un rack équipé de 72 GPU NVIDIA Blackwell fonctionnant ensemble comme s’ils n’en formaient qu’un, offrant une performance IA de 1,4 exaflops et 30 To de mémoire rapide et partagée. Les 72 GPU sont connectés à l’aide de NVIDIA NVSwitch dans une seule et même structure massive d’interconnexion NVLink, qui permet à chaque GPU de communiquer avec les autres grâce à une connectivité NVLink de 130 To/s.
Les modèles MoE peuvent exploiter cette conception pour étendre le parallélisme des experts bien au-delà des limites précédentes, en répartissant les experts sur un ensemble beaucoup plus large pouvant compter jusqu’à 72 GPU.
Cette approche architecturale résout directement les goulots d’étranglement de la mise à l’échelle MoE en :
- Réduisant le nombre d’experts par GPU : la répartition des experts sur un maximum de 72 GPU réduit le nombre d’experts par GPU, minimisant ainsi la pression de chargement des paramètres sur la mémoire à haut débit de chaque GPU. La réduction du nombre d’experts par GPU libère également de l’espace mémoire, ce qui permet à chaque GPU de servir plus d’utilisateurs simultanés et de prendre en charge des longueurs d’entrée plus longues.
- Accélérant la communication entre les experts : les experts répartis sur les GPU peuvent communiquer entre eux instantanément à l’aide de NVLink. Le switch NVLink dispose également de la puissance de calcul nécessaire pour effectuer certains des calculs requis pour combiner les informations provenant de divers experts, ce qui accélère la réponse finale.
D’autres optimisations full-stack jouent également un rôle clé dans l’obtention de performances d’inférence élevées pour les modèles MoE. Le framework NVIDIA Dynamo orchestre la désagrégation du service (disaggragated serving) en attribuant les tâches de préremplissage et de décodage à différents GPU, ce qui permet au décodage de s’exécuter avec un grand parallélisme d’experts, tandis que le préremplissage utilise des techniques de parallélisme mieux adaptées à sa charge de travail. Le format NVFP4 permet de maintenir l’exactitude tout en améliorant encore les performances et l’efficacité.
Des bibliothèques open source, telles que NVIDIA TensorRT-LLM, SGLang et vLLM, prennent en charge ces optimisations pour les modèles MoE. SGLang, en particulier, a joué un rôle important dans l’avancement du MoE à grande échelle sur GB200 NVL72, contribuant à valider et à perfectionner bon nombre des techniques utilisées aujourd’hui.
Afin d’offrir ces performances aux entreprises du monde entier, le GB200 NVL72 est déployé par les principaux fournisseurs de services cloud et les NVIDIA Cloud Partners, parmis lesquels Amazon Web Services, Core42, CoreWeave, Crusoe, Google Cloud, Lambda, Microsoft Azure, Nebius, Nscale, Oracle Cloud Infrastructure, Together AI, et d’autres.
« Chez CoreWeave, nos clients exploitent notre plateforme pour mettre en production des modèles “mixture of experts” tout en créant des workflows agentiques », explique Peter Salanki, cofondateur et chief technology officer chez CoreWeave. « En collaborant étroitement avec NVIDIA, nous sommes en mesure de fournir une plateforme étroitement intégrée qui réunit les performances, l’évolutivité et la fiabilité des modèles MoE en un seul endroit. Cela n’est possible que sur un cloud spécialement conçu pour l’IA. »
Des clients tels que DeepL utilisent la conception à l’échelle du rack Blackwell NVL72 pour créer et déployer leurs modèles d’IA de nouvelle génération.
« DeepL exploite le matériel NVIDIA GB200 pour former des modèles “mixture of experts”, faisant progresser son architecture de modèle afin d’améliorer l’efficacité pendant l’entrainement et l’inférence, et établissant ainsi de nouvelles références en matière de performances dans le domaine de l’IA », a déclaré Paul Busch, research team lead chez DeepL.
La preuve réside dans les performances par watt
Le NVIDIA GB200 NVL72 adapte efficacement les modèles MoE complexes et offre un gain de performance par watt multiplié par 10. Cette avancée en termes de performance n’est pas qu’une simple mesure ; en multipliant par dix les revenus générés par les jetons, elle transforme l’économie de l’IA à grande échelle dans les centres de données soumis à des contraintes d’énergie et de coûts.
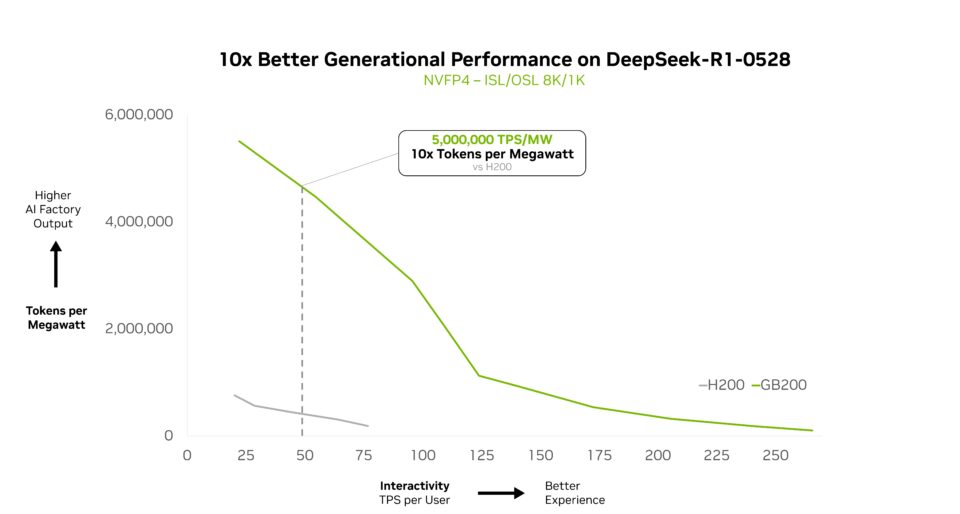
Depuis début 2025, presque tous les modèles de pointe principaux utilisent le MoE.
Lors de la conférence NVIDIA GTC à Washington, D.C., Jensen Huang, fondateur et CEO de NVIDIA, a souligné que le GB200 NVL72 offre des performances 10 fois supérieures à celles du NVIDIA Hopper pour DeepSeek-R1, et que ces performances s’étendent également à d’autres variantes de DeepSeek.
« Grâce au GB200 NVL72 et aux optimisations personnalisées de Together AI, nous dépassons les attentes des clients en matière de charge de travail d’inférence à grande échelle pour les modèles MoE tels que DeepSeek-V3 », a déclaré Vipul Ved Prakash, cofondateur et CEO de Together AI. « Les gains de performance proviennent des optimisations full-stack de NVIDIA, associées aux avancées de Together AI au travers des kernels, du moteur d’exécution et du décodage spéculatif. »
Cet avantage en termes de performances se vérifie sur d’autres modèles de pointe.
Kimi K2 Thinking, le modèle open source le plus intelligent, en est une autre preuve, avec des performances générationnelles 10 fois supérieures lorsqu’il est déployé sur GB200 NVL72.
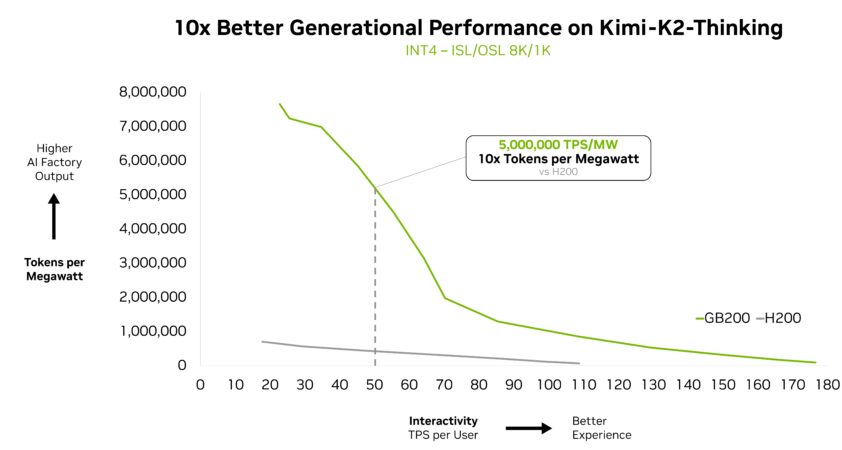
Fireworks AI a actuellement déployé Kimi K2 sur la plateforme NVIDIA B200 atteignant les meilleures performances dans le classement Artificial Analysis.
« La conception à l’échelle d’un rack du NVIDIA GB200 NVL72 rend le modèle MoE nettement plus efficace », a déclaré Lin Qiao, cofondateur et CEO de Fireworks AI. « À l’avenir, le NVL72 a le potentiel de transformer la façon dont nous utilisons les modèles MoE massifs, en offrant des améliorations de performances majeures par rapport à la plateforme Hopper et en établissant une nouvelle référence en matière de vitesse et d’efficacité des modèles de pointe. »
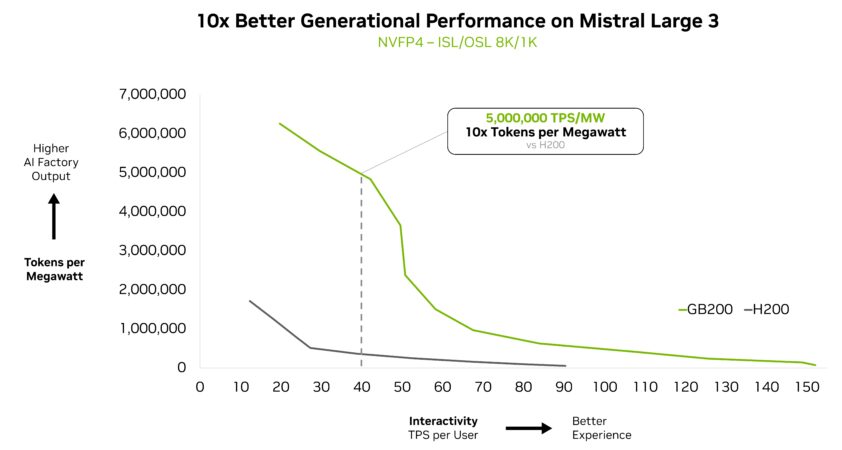
Le nouveau modèle Mistral Large 3 a également obtenu un gain de performances 10 fois supérieur sur le GB200 NVL72 par rapport à la génération précédente H200. Ce gain générationnel se traduit par une meilleure expérience utilisateur, un coût par token réduit et une efficacité énergétique accrue pour ce nouveau modèle MoE.
Une intelligence à grande échelle
Le système rack NVIDIA GB200 NVL72 est conçu pour offrir des performances prometteuses au-delà des modèles MoE.
La raison devient évidente lorsque l’on examine l’orientation prise par l’IA : la dernière génération de modèles d’IA multimodaux dispose de composants spécialisés pour le langage, la vision, l’audio et d’autres modalités, n’activant que les plus pertinents pour la tâche à accomplir.
Dans les systèmes agentiques, différents « agents » se spécialisent dans la planification, la perception, le raisonnement, l’utilisation d’outils ou la recherche, et un orchestrateur les coordonne pour obtenir un résultat unique. Dans les deux cas, le modèle de base reflète le MoE : acheminer chaque partie du problème vers les experts les plus pertinents, puis coordonner leurs résultats pour produire le résultat final.
L’extension de ce principe aux environnements de production où plusieurs applications et agents servent plusieurs utilisateurs permet d’atteindre de nouveaux niveaux d’efficacité. Au lieu de dupliquer des modèles d’IA massifs pour chaque agent ou application, cette approche permet de créer un panel d’experts accessible à tous, chaque demande étant acheminée vers l’expert approprié.
Le MoE est une architecture puissante qui fait évoluer le secteur vers un avenir où coexistent capacités massives, efficacité et échelle. Le GB200 NVL72 libère ce potentiel, et la feuille de route de NVIDIA, qui comprend l’architecture NVIDIA Vera Rubin, continuera à élargir les horizons des modèles de pointe.
En savoir plus sur la façon dont GB200 NVL72 adapte les modèles MoE complexes dans cette analyse technique approfondie.