La plateforme de calcul accéléré de NVIDIA domine les benchmarks de supercalcul autrefois dominés par les CPU, permettant une efficacité de l’IA, de la science, des affaires et du calcul dans le monde entier.
La loi de Moore a suivi son cours, et le traitement parallèle est la voie à suivre. Grâce à cette évolution, les plateformes GPU NVIDIA sont désormais idéalement positionnées pour répondre aux trois lois de mise à l’échelle — pré-entraînement, post-entraînement et calcul en temps de test — des systèmes de recommandation nouvelle génération aux grands modèles linguistiques (grands modèles linguistiques, LLM) en passant par les agents d’IA et bien plus encore.
- Comment NVIDIA a transformé les bases de l’informatique
- Le pré-entraînement, le post-entraînement et l’inférence de l’IA repoussent la frontière
- Comment les hyperscalers utilisent l’IA pour transformer les systèmes de recherche et de recommandation
La transition du CPU au GPU : un changement historique dans le calcul 🔗
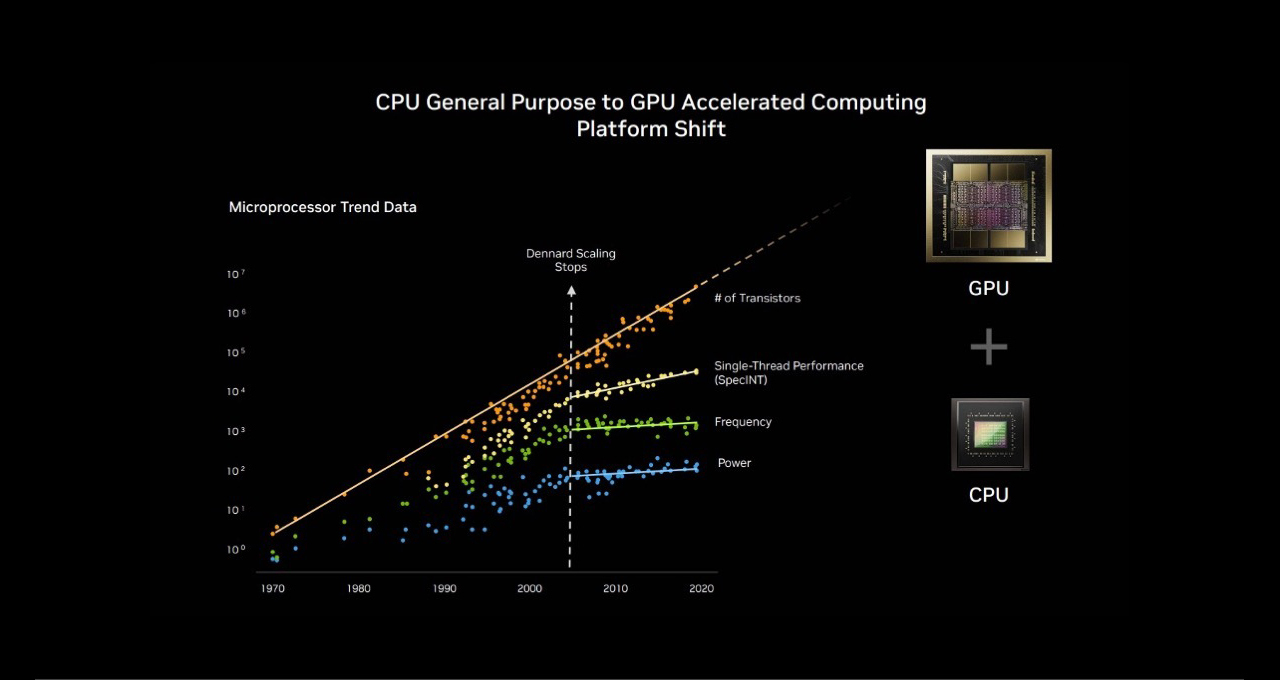
Lors du SC25, le fondateur et PDG de NVIDIA, Jensen Huang, a mis en évidence l’évolution du paysage. Au sein du TOP100, un sous-ensemble de la liste de supercalculateurs TOP500, plus de 85 % des systèmes utilisent des GPU. Cette évolution représente une transition historique du paradigme de traitement série des CPU aux architectures accélérées massivement parallèles.
![]()
Avant 2012, l’apprentissage automatique était basé sur la logique programmée. Les modèles statistiques étaient utilisés et fonctionnaient efficacement sur des CPU sous forme de corpus de règles codées en dur. Mais tout cela a changé lorsqu’AlexNet sur des GPU de jeu a démontré que la classification d’images pouvait être apprise au moyen d’exemples. Ses implications étaient énormes pour l’avenir de l’IA, le traitement parallèle sur des sommes de données croissantes sur des GPU entraînant une nouvelle vague de calcul.
Cette évolution ne concerne pas seulement le matériel. Il s’agit de plateformes qui débloquent une nouvelle science. Les GPU offrent beaucoup plus d’opérations par watt, ce qui rend l’exascale pratique sans demandes d’énergie insoutenables.
Les résultats récents du Green500, un classement des supercalculateurs les plus écoénergétiques au monde, soulignent le contraste entre les GPU et les CPU. Les cinq meilleures performances de ce benchmark standard du secteur étaient toutes des GPU NVIDIA, offrant une moyenne de 70,1 gigaflops par watt. Pendant ce temps, les meilleurs systèmes CPU uniquement fournissaient 15,5 flops par watt en moyenne. Cet écart de 4,5 fois entre les GPU et les CPU en matière d’efficacité énergétique met en évidence l’avantage considérable en matière de TCO (coût total de possession) de la migration de ces systèmes vers les GPU.
Une autre mesure de l’efficacité énergétique et de la différence de performances entre le CPU et le GPU est arrivée avec les résultats de NVIDIA sur le Graph500. NVIDIA a fourni un résultat record avec 410 000 milliards de bords traversés par seconde, se classant à la première place de la liste de recherche de Graph500.
La série gagnante a plus que doublé le score suivant et a utilisé 8 192 GPU NVIDIA H100 pour traiter un graphique avec 2,2 trillions de sommets et 35 trillions d’arêtes. À comparer au meilleur résultat de la liste, qui nécessitait environ 150 000 CPU pour cette charge de travail. Les réductions de l’empreinte matérielle de cette échelle permettent de gagner du temps, de l’argent et de l’énergie.
Pourtant, NVIDIA a montré lors du SC25 que sa plateforme de supercalcul d’IA était bien plus que des GPU. La mise en réseau, les bibliothèques CUDA, la mémoire, le stockage et l’orchestration sont conçus conjointement pour fournir une plateforme complète.

Grâce à CUDA, NVIDIA est une plateforme complète. Les bibliothèques et les frameworks open-source, tels que ceux de l’écosystème CUDA-X, sont là où se produisent des accélérations importantes. Snowflake a récemment annoncé l’intégration de GPU NVIDIA A10 pour booster les workflows de Data Science. Snowflake ML est désormais préinstallé avec les bibliothèques NVIDIA cuML et cuDF pour accélérer les algorithmes ML populaires avec ces GPU.
Grâce à cette intégration native, les utilisateurs de Snowflake peuvent facilement accélérer les cycles de développement de modèles sans devoir modifier le code. Les benchmarks de NVIDIA montrent que le temps nécessaire pour Random Forest est cinq fois moins et jusqu’à 200 fois moins pour HDBSCAN sur les GPU NVIDIA A10 par rapport aux CPU.
Le basculement a été le point tournant. Les lois de mise à l’échelle sont la trajectoire vers l’avant. À chaque étape, les GPU sont le moteur qui propulse l’IA vers le prochain chapitre.
Mais c’est sur CUDA-X et de nombreux cadres et bibliothèques logicielles open-source que se produit une grande partie de la magie. Les bibliothèques CUDA-X accélèrent les charges de travail dans tous les secteurs et toutes les applications : ingénierie, finance, analyse de données, génomique, biologie, chimie, télécommunications, robotique et bien plus encore.
« Le monde a réalisé des investissements massifs dans des logiciels non liés à l’intelligence artificielle. Du traitement des données aux simulations scientifiques et d’ingénierie, ce qui représente des centaines de milliards de dollars en Cloud Computing chaque année », a déclaré Huang lors du récent appel sur les gains de NVIDIA.
De nombreuses applications qui fonctionnaient auparavant exclusivement sur des CPU passent désormais rapidement aux GPU CUDA. « Le calcul accéléré a atteint un point de basculement. L’IA a également atteint un point de basculement et transforme les applications existantes tout en en permettant de nouvelles applications », a-t-il déclaré.

Ce qui avait commencé comme un impératif d’efficacité énergétique est devenu une plateforme scientifique : la simulation et l’IA fusionnées à grande échelle. Le leadership des GPU NVIDIA dans le TOP 100 est à la fois la preuve de cette trajectoire et le signal de ce qui va suivre : des avancées dans toutes les disciplines.
Les chercheurs peuvent désormais entraîner des modèles à des trillions de paramètres, simuler des réacteurs de fusion et accélérer la découverte de médicaments à une échelle que les CPU seuls ne pourraient jamais atteindre.
Les trois lois de mise à l’échelle qui poussent la nouvelle frontière de l’IA 🔗
Le passage des CPU aux GPU n’est pas seulement une étape en matière de supercalcul. C’est la base des trois lois de mise à l’échelle qui représentent la feuille de route du prochain workflow de l’IA : le pré-entraînement, le post-entraînement et la mise à l’échelle pendant le test.
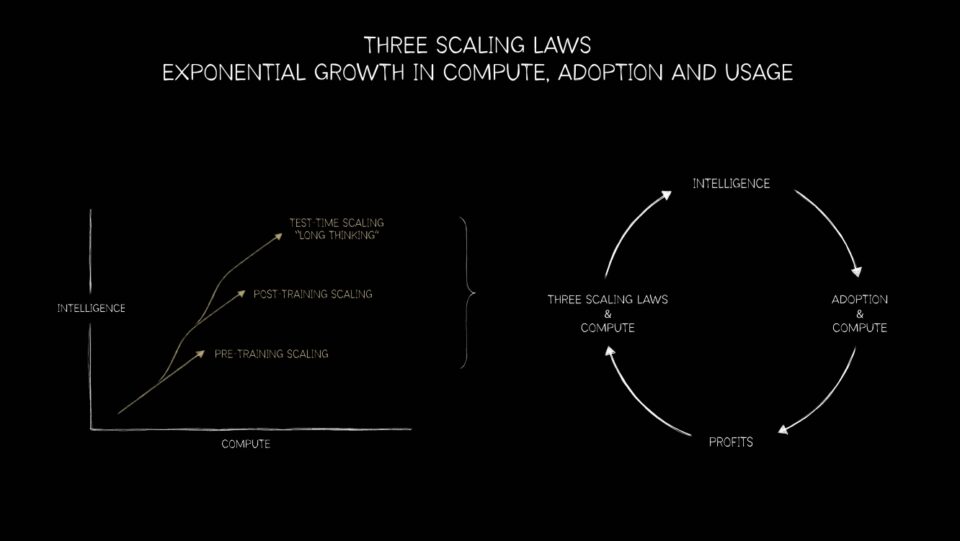
La mise à l’échelle du pré-entraînement était la première loi à aider le secteur. Les chercheurs ont découvert que, à mesure que les jeux de données, le nombre de paramètres et le calcul augmentaient, les performances des modèles s’amélioraient de manière prévisible. Le doublement des données ou des paramètres impliquait des progrès en matière de précision et de polyvalence.
Sur les derniers benchmarks industriels MLPerf Training, la plateforme NVIDIA a offert les performances les plus élevées pour tous les tests et était la seule plateforme à soumettre sur tous les tests. Sans GPU, l’ère de la recherche sur l’IA au « plus grand, c’est mieux » aurait stagné sous le poids des budgets énergétiques et des contraintes de temps.
La mise à l’échelle post-entraînement prolonge l’histoire. Une fois qu’un modèle de base est créé, il doit être affiné, en fonction des industries, des langues ou des contraintes de sécurité. Les techniques telles que l’apprentissage par renforcement à partir du feedback humain, l’élagage et la distillation nécessitent d’énormes capacités de calcul supplémentaires. Dans certains cas, les exigences rivalisent avec le pré-entraînement lui-même. C’est comme un élève qui s’améliore après l’enseignement de base. Les GPU fournissent une fois de plus la puissance requise, permettant un réglage fin et une adaptation continus dans tous les domaines.
La mise à l’échelle pendant le test, la nouvelle loi, pourrait s’avérer la plus transformatrice. Les modèles modernes basés sur des architectures à mélange d’experts peuvent raisonner, planifier et évaluer plusieurs solutions en temps réel. Le raisonnement par chaîne de pensée, la recherche générative et l’IA agentique exigent un calcul dynamique et récursif, dépassant souvent les exigences de pré-entraînement. Cette étape stimulera la demande exponentielle en infrastructure d’inférence, des centres de données aux appareils Edge.
Ensemble, ces trois lois expliquent la demande de GPU pour les nouvelles charges de travail d’IA. La mise à l’échelle du pré-entraînement a rendu les GPU indispensables. La mise à l’échelle post-entraînement a renforcé leur rôle en matière d’affinement. La mise à l’échelle du temps de test garantit que les GPU restent essentiels longtemps après la fin de l’entraînement. C’est le nouveau chapitre du calcul accéléré : un cycle de vie où les GPU alimentent chaque étape de l’IA, de l’apprentissage au déploiement, en passant par le raisonnement.
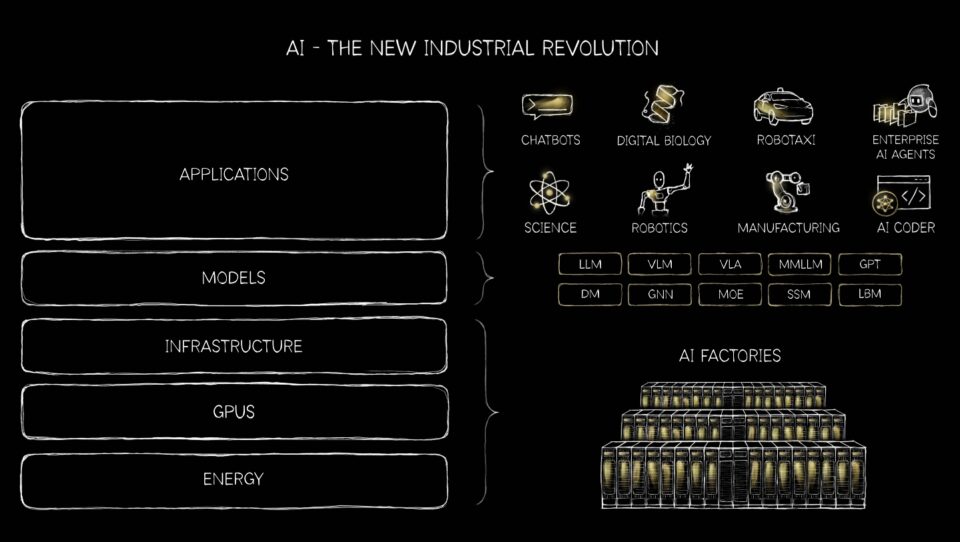
IA générative, agentique, physique et au-delà 🔗
Le monde de l’IA s’étend bien au-delà des systèmes de recommandation de base, des chatbots et de la génération de texte. Les VLM, ou modèles de langage visuel, sont des systèmes d’IA combinant la vision par ordinateur et le traitement du langage naturel pour comprendre et interpréter les images et le texte. Les systèmes de recommandation, qui sont les moteurs des achats personnalisés, du streaming et des flux sociaux, ne sont qu’un exemple parmi de nombreux autres de la façon dont la transition massive des CPU aux GPU transforme l’IA.
L’IA générative transforme tout, de la robotique et des véhicules autonomes aux entreprises de logiciels en tant que service, et représente un investissement massif dans les startups.
Les plateformes NVIDIA sont les seules à s’exécuter sur tous les principaux modèles d’IA générative et à gérer 1,4 million de modèles open-source.
Autrefois contraints par les architectures CPU, les systèmes de recommandation avaient du mal à capturer la complexité du comportement des utilisateurs à grande échelle. Avec les GPU CUDA, la mise à l’échelle du pré-entraînement permet aux modèles d’apprendre à partir d’énormes jeux de données de clics, d’achats et de préférences, découvrant des modèles plus riches. La mise à l’échelle post-entraînement optimise ces modèles pour des domaines spécifiques, en affinant la personnalisation pour des secteurs, de la vente au détail au divertissement. Sur les principaux sites en ligne mondiaux, même un gain de 1 % en matière de pertinence des recommandations peut générer des milliards de ventes supplémentaires.
Les ventes de commerce électronique devraient atteindre 6 400 milliards de dollars dans le monde entier d’ici 2025, selon Emarketer.
Les hyperscalers du monde entier, une industrie qui pèse des milliers de milliards de dollars, transforment la recherche, les recommandations et la compréhension du contenu, de l’apprentissage automatique classique à l’IA générative. NVIDIA CUDA excelle dans les deux domaines et est la plateforme idéale pour cette transition, qui stimule les investissements d’infrastructure mesurés à des centaines de milliards de dollars.
Désormais, la mise à l’échelle du temps de test transforme l’inférence elle-même : les moteurs de recommandation peuvent raisonner de manière dynamique, en évaluant plusieurs options en temps réel pour fournir des suggestions contextuelles. Le résultat est un bond en avant en matière de précision et de pertinence, des recommandations qui ressemblent moins à des listes statiques qu’à des conseils intelligents. Les GPU et les lois de mise à l’échelle transforment les recommandations d’une fonctionnalité d’arrière-plan en une capacité de première ligne de l’IA agentique, permettant à des milliards de personnes de trier des trillions d’éléments sur Internet avec une facilité qui serait autrement impossible.
Ce qui a commencé comme des interfaces conversationnelles basées sur des modèles de langage étendu (LLM) évolue désormais vers des systèmes autonomes intelligents prêts à remodeler presque tous les secteurs de l’économie mondiale.
Nous connaissons une évolution fondamentale, de l’IA en tant que technologie virtuelle à l’IA entrant dans le monde physique. Cette transformation exige rien de moins qu’une croissance explosive de l’infrastructure informatique et de nouvelles formes de collaboration entre les humains et les machines.
L’IA générative s’est avérée capable de créer non seulement de nouveaux textes et images, mais aussi du code, des conceptions et même des hypothèses scientifiques. L’IA agentique arrive maintenant : des systèmes qui perçoivent, raisonnent, planifient et agissent de manière autonome. Ces agents se comportent moins comme des outils que comme des collègues numériques, effectuant des tâches complexes en plusieurs étapes dans tous les secteurs. De la recherche juridique à la logistique, l’IA agentique promet d’accélérer la productivité en servant de travailleurs numériques autonomes.
L’IA physique est peut-être le bond le plus transformateur, l’incarnation de l’intelligence dans des robots de toutes les formes. Trois ordinateurs sont nécessaires pour créer des robots physiques incarnés par l’IA : NVIDIA DGX GB300 pour entraîner le modèle d’action vision-langage de raisonnement, NVIDIA RTX PRO pour simuler, tester et valider le modèle dans un monde virtuel basé sur Omniverse et Jetson Thor pour exécuter le VLA de raisonnement à une vitesse en temps réel.
La robotique va connaître une avancée majeure au cours des prochaines années, avec des robots mobiles autonomes, des robots collaboratifs et des humanoïdes perturbant la fabrication, la logistique et la santé. Morgan Stanley estime qu’il y aura 1 milliard de robots humanoïdes avec 5 trillions de dollars de revenus d’ici 2050.
Cela montre à quel point l’IA va s’intégrer à l’économie physique, et ce n’est qu’un avant-goût de ce qui est au programme.

L’IA n’est plus seulement un outil. Il effectue du travail et se présente pour transformer chacun des mille milliards de dollars en marchés au monde. Et un cycle vertueux d’IA est arrivé, modifiant fondamentalement l’ensemble de la pile de calcul, transformant tous les ordinateurs en nouvelles plateformes de supercalcul pour des opportunités beaucoup plus grandes.