
Note de l’éditeur : cet article, à l’origine publié le 15 novembre 2023, a été mis à jour.
Pour comprendre les avancées récentes de l’IA générative, imaginez une salle d’audience.
Les juges délibèrent et tranchent quant aux affaires en fonction de leur compréhension du droit. Parfois, une affaire, comme une poursuite pour faute professionnelle ou un litige sur le travail, nécessite une expertise spéciale, et les juges envoient alors des greffiers consulter une bibliothèque juridique à la recherche de jurisprudences qu’ils pourront citer.
Comme tout bon juge, les grands modèles de langage (LLM) peuvent répondre à une grande variété de requêtes humaines. Mais pour fournir des réponses faisant autorité et citant des sources, le modèle a besoin d’un assistant pour effectuer des recherches.
En IA, le greffier est un processus appelé génération augmentée par récupération, ou RAG en abrégé.
Pourquoi le nom « RAG » ?
Patrick Lewis a inventé le terme dans son rapport de 2020 et s’est excusé pour l’acronyme peu flatteur (rag signifie « chiffon » ou « guenille » en anglais), qui décrit désormais un ensemble croissant de méthodes dans des centaines d’articles et des dizaines de services commerciaux qui, selon lui, représentent l’avenir de l’IA générative.

« Nous aurions certainement davantage réfléchi à ce nom si nous avions su que notre travail prendrait de telles proportions », a déclaré Patrick Lewis dans une interview à Singapour où il se trouvait pour partager ses idées lors d’une conférence régionale de développeurs de bases de données.
« Nous pensions trouver un nom plus agréable, mais au moment de rédiger le rapport, personne n’a eu de meilleure idée », explique-t-il, alors qu’il dirige désormais une équipe RAG pour la startup Cohere, spécialisée dans l’IA.
Alors, qu’est-ce que la génération augmentée par récupération (RAG) ?
La génération augmentée par récupération (RAG) est une technique permettant d’améliorer la précision et la fiabilité des modèles d’IA générative à l’aide de faits provenant de sources externes.
En d’autres termes, elle comble un manque dans le fonctionnement des LLM. Les LLM sont des réseaux neuronaux, généralement mesurés par le nombre de paramètres qu’ils comportent. Les paramètres d’un LLM représentent essentiellement les schémas généraux de l’utilisation des mots dans les phrases par les humains.
Cette compréhension détaillée, parfois appelée connaissance paramétrée, rend les LLM utiles pour répondre aux invites générales à la vitesse de l’éclair. Cependant, elle n’est pas utile aux utilisateurs qui souhaitent approfondir un sujet spécifique.
Combiner des ressources internes et externes
Patrick Lewis et ses collègues ont développé la génération augmentée par récupération pour lier les services d’IA générative à des ressources externes, notamment celles qui contiennent beaucoup de détails techniques récents.
Les auteurs du document sont issus de l’ex Facebook AI Research (aujourd’hui Meta AI), de l’University College London et de l’université de New York. Dans leur travail, ils ont qualifié la RAG de « recette de réglage généraliste », car elle peut être utilisée par presque n’importe quel LLM pour se connecter avec pratiquement n’importe quelle ressource externe.
Instaurer la confiance auprès de l’utilisateur
La génération augmentée par récupération donne aux modèles des sources qu’ils peuvent citer, comme des notes de bas de page dans un document de recherche, de sorte que les utilisateurs peuvent vérifier les affirmations. Cela instaure la confiance.
De plus, la technique peut aider les modèles à dissiper les ambiguïtés dans une requête utilisateur. Elle réduit également la possibilité qu’un modèle fasse une mauvaise supposition, un phénomène parfois appelé hallucination.
Autre avantage de taille : la RAG est relativement simple. Dans un article de blog, Patrick Lewis et trois des coauteurs du rapport ont déclaré que les développeurs peuvent implémenter le processus avec seulement cinq lignes de code.
De quoi rendre la méthode plus rapide et moins coûteuse que de réentraîner un modèle avec des ensembles de données supplémentaires. Elle permet en outre aux utilisateurs de changer les sources en temps réel.
Comment utilise-t-on la RAG ?
La génération augmentée par récupération permet en quelque sorte aux utilisateurs de dialoguer avec des référentiels de données. De quoi ouvrir la voie à de nouvelles d’expériences. Cela signifie que les applications de la RAG pourraient être plusieurs fois le nombre d’ensembles de données disponibles.
Par exemple, un modèle d’IA générative complété par un index médical pourrait être un excellent assistant pour le personnel médical. Les analystes financiers bénéficieraient d’un assistant lié aux données du marché.
D’ailleurs, presque toutes les entreprises peuvent transformer leurs manuels techniques, règlements, vidéos ou journaux en ressources appelées bases de connaissances et capables d’améliorer les LLM. Ces sources peuvent favoriser des cas d’utilisation comme l’assistance client ou sur le terrain, la formation des employés et la productivité des développeurs.
Ce vaste potentiel explique pourquoi des entreprises comme AWS, IBM, Glean, Google, Microsoft, NVIDIA, Oracle et Pinecone adoptent la RAG.
Premiers pas avec la génération augmentée par récupération
Pour aider les utilisateurs à se lancer, NVIDIA a développé un modèle d’IA pour créer des assistants virtuels. Les entreprises peuvent utiliser cette architecture de référence pour faire évoluer rapidement leurs opérations de service client avec l’IA générative et la RAG, ou créer une nouvelle solution centrée sur le client.
Le modèle utilise certaines des méthodes de développement d’IA les plus récentes ainsi que NVIDIA NeMo Retriever, une collection de microservices NIM NVIDIA faciles d’utilisation pour la récupération d’informations à grande échelle. Les microservices NIM facilitent le déploiement d’une inférence de modèles d’IA sécurisée et hautes performances dans le cloud, les datacenters et les stations de travail.
Ces composants font tous partie de NVIDIA AI Enterprise, une plateforme logicielle qui accélère le développement et le déploiement d’une IA prête pour la production avec la sécurité, l’assistance et la stabilité nécessaires aux entreprises.
Il existe également une formation pratique gratuite NVIDIA LaunchPad pour développer des chatbots d’IA à l’aide de la RAG, afin que les développeurs et les équipes informatiques puissent générer rapidement et avec précision des réponses basées sur les données de l’entreprise.
Obtenir les meilleures performances des workflows RAG nécessite d’énormes quantités de mémoire et de calcul pour déplacer et traiter les données. La NVIDIA GH200 Grace Hopper Superchip, avec ses 288 Go de mémoire HBM3e rapide et 8 pétaflops de calcul, est idéale : elle peut accélérer le processus par un facteur de 150 par rapport à un CPU.
Une fois que les entreprises se sont familiarisées avec la RAG, elles peuvent combiner une variété de LLM prêts à l’emploi ou personnalisés avec des bases de connaissances internes ou externes, afin de créer une large gamme d’assistants capables d’aider leurs employés et leurs clients.
La RAG ne nécessite pas de datacenter. Les LLM font leurs débuts sur les PC Windows, grâce au logiciel NVIDIA qui permet aux utilisateurs d’accéder à toutes sortes d’applications, y compris sur leurs ordinateurs portables.

Les PC équipés de GPU NVIDIA RTX peuvent désormais exécuter localement certains modèles d’IA. En utilisant la RAG sur un PC, les utilisateurs peuvent lier une source de connaissances privée (e-mails, notes, articles…) pour améliorer les réponses. L’utilisateur a alors la garantie que sa source de données, ses invites et sa réponse restent privées et sécurisées.
Un article récent fournit un exemple de RAG accélérée par TensorRT-LLM pour Windows afin d’obtenir de meilleurs résultats rapidement.
Histoire de la RAG
Les racines de la technique remontent au moins au début des années 1970. À cette époque, les chercheurs en récupération d’informations ont prototypé ce qu’ils appelaient des systèmes de réponse aux questions : des applications utilisant le traitement du langage naturel (NLP) pour accéder au texte, au départ dans des domaines précis comme le baseball.
Les concepts derrière ce type d’exploration de texte sont restés assez stables au fil des ans. Mais les moteurs d’apprentissage automatique sur lesquels ils reposent se sont développés de manière significative, augmentant leur utilité et leur popularité.
Au milieu des années 1990, le service Ask Jeeves, désormais Ask.com, a popularisé les réponses aux questions avec sa mascotte de valet bien habillé. Watson, d’IBM, est devenu une célébrité en 2011 lorsqu’il a battu deux champions humains dans l’émission télévisée Jeopardy!
Aujourd’hui, les LLM font passer les systèmes de réponse aux questions à la vitesse supérieure.
Des perspectives issues d’un laboratoire londonien
Le rapport fondateur de 2020 a été publié tandis que Patrick Lewis poursuivait un doctorat en NLP à l’University College London et travaillait pour Meta dans un nouveau laboratoire d’IA de Londres. L’équipe cherchait des moyens d’intégrer plus de connaissances dans les paramètres d’un LLM en utilisant un benchmark qu’elle avait développé pour mesurer sa progression.
Le groupe, inspiré par un article de chercheurs Google, se fondait sur des méthodes antérieures et « avait cette vision motivante d’un système entraîné doté d’un index de récupération, de sorte qu’il pouvait apprendre et générer n’importe quel texte souhaité », se souvient Patrick Lewis.
 Le système de réponse aux questions IBM Watson est devenu célèbre en remportant le gros lot dans l’émission télévisée Jeopardy!
Le système de réponse aux questions IBM Watson est devenu célèbre en remportant le gros lot dans l’émission télévisée Jeopardy!
Lorsque Patrick Lewis a intégré au processus le système de récupération prometteur d’une autre équipe Meta, ses premiers résultats furent étonnamment impressionnants.
« Je les ai montrés à mon superviseur et il a dit : « Ouah, savoure ta victoire. Ce genre de chose n’arrive pas souvent », car ces workflows peuvent être difficiles à mettre en place correctement la première fois », a-t-il déclaré.
Patrick Lewis mentionne aussi les contributions majeures des membres de l’équipe, Ethan Perez et Douwe Kiela, qui travaillent alors respectivement à l’université de New York et à Facebook AI Research.
Une fois terminé, le projet fonctionnait sur un cluster de GPU NVIDIA et montrait comment rendre les modèles d’IA générative plus fiables. Il a depuis été cité par des centaines d’articles ayant amplifié et étendu les concepts dans ce qui reste un domaine de recherche actif.
Fonctionnement de la génération augmentée par récupération
Globalement, voici comment un dossier technique NVIDIA décrit le processus RAG.
Lorsque les utilisateurs posent une question à un LLM, le modèle d’IA envoie la requête à un autre modèle qui la transforme en format numérique lisible par les machines. La version numérique de la requête est parfois appelée intégration ou vecteur.
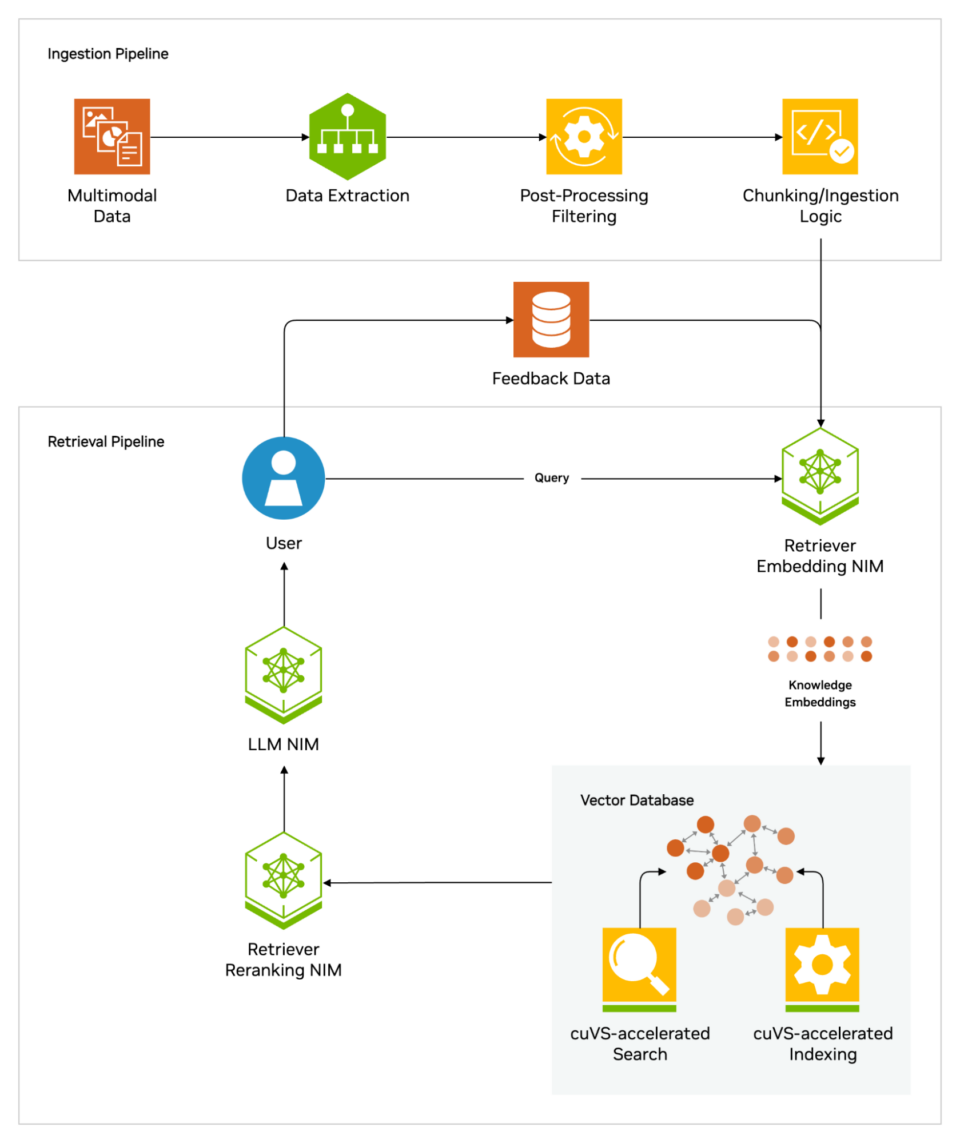
La génération augmentée par récupération combine des LLM avec des modèles d’intégration et des bases de données vectorielles.
Le modèle d’intégration compare ensuite ces valeurs numériques à des vecteurs dans un index lisible par machine d’une base de connaissances disponible. Lorsqu’il trouve une ou plusieurs correspondances, il récupère les données, les transforme en mots lisibles par l’homme et les renvoie au LLM.
Enfin, le LLM combine les mots récupérés et sa propre réponse à la requête en une réponse finale qu’il présente à l’utilisateur, en citant potentiellement les sources du modèle d’intégration trouvé.
Maintenir les sources à jour
En arrière-plan, le modèle d’intégration crée et met à jour en permanence des indices lisibles par machine, parfois appelés bases de données vectorielles, pour créer de nouvelles bases de connaissances et les mettre à jour à mesure qu’elles deviennent disponibles.
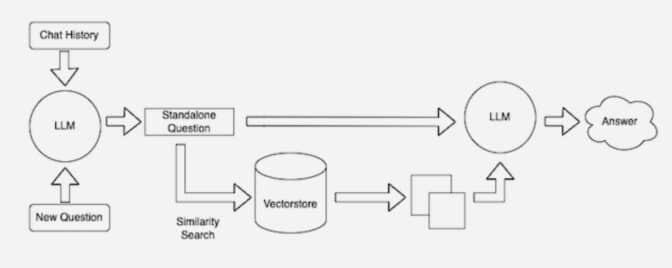
De nombreux développeurs trouvent que LangChain, une bibliothèque open source, peut être très utile pour enchaîner LLM, modèles d’intégration et bases de connaissances. NVIDIA utilise LangChain dans son architecture de référence pour la génération augmentée par récupération.
La communauté LangChain fournit sa propre description d’un processus RAG.
L’avenir de l’IA générative réside dans l’enchaînement créatif de toutes sortes de LLM et de bases de connaissances pour créer de nouveaux types d’assistants dont les résultats font autorité et que les utilisateurs peuvent vérifier.
Découvrez les sessions et les expériences d’IA générative à la NVIDIA GTC, la conférence mondiale sur l’IA et le calcul accéléré, qui se tiendra du 18 au 21 mars à San Jose, en Californie, et en ligne.