
Note de l’éditeur : cet aricle fait partie de Think SMART, une série sur la façon dont principaux fournisseurs de services, développeurs et entreprises spécialisés dans l’IA peuvent améliorer leurs performances d’inférence et leur retour sur investissement grâce aux dernières avancées de la plateforme d’inférence complète de NVIDIA.
NVIDIA Blackwell offre les performances et l’efficacité les plus élevées, et le coût total de possession le plus bas sur chaque modèle testé et cas d’utilisation dans le dernier benchmark indépendant SemiAnalysis InferenceMAX v1.
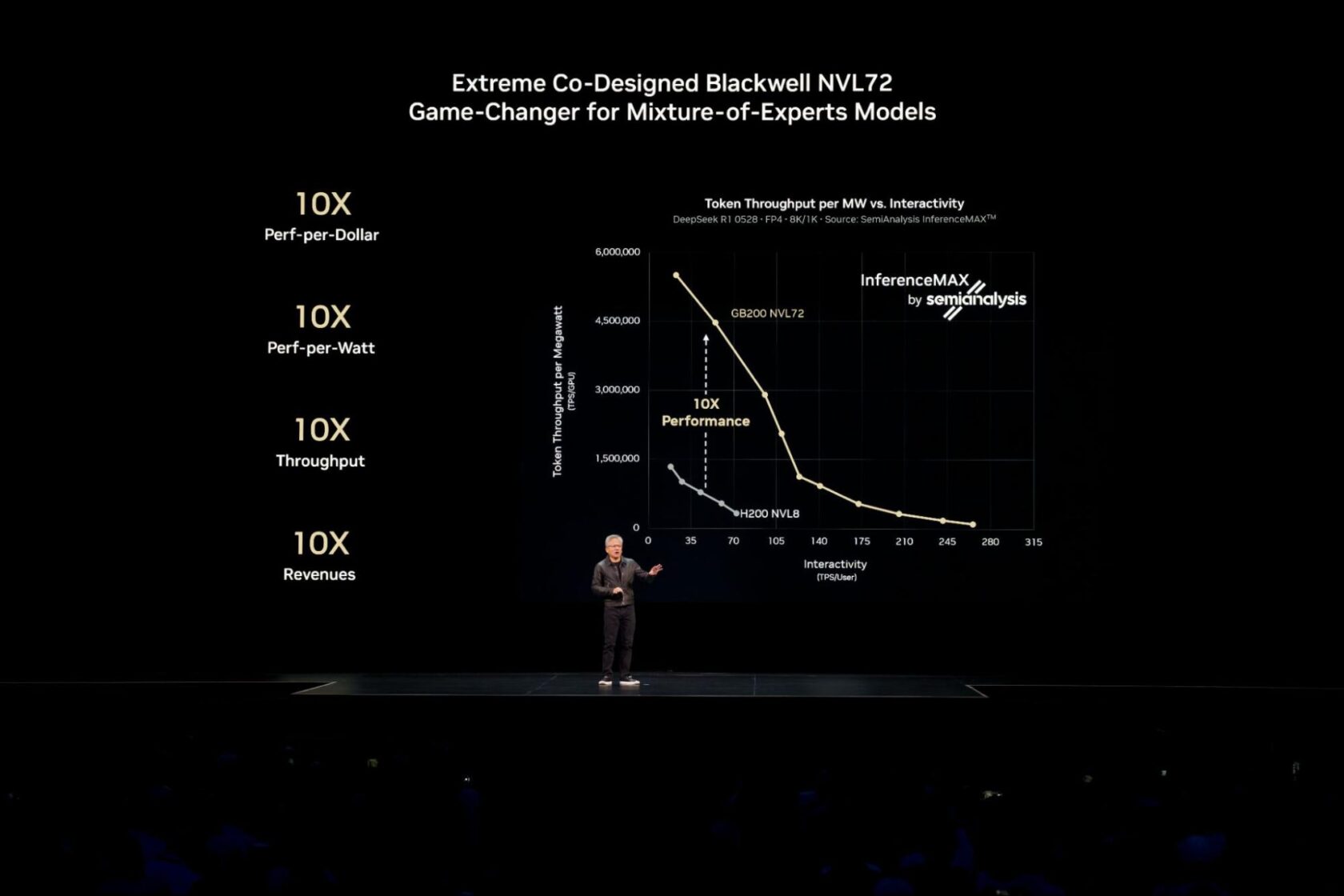
Jensen Huang, PDG de NVIDIA, a souligné lors de la conférence NVIDIA GTC à Washington D.C. que Blackwell offre des performances 10 fois supérieures à celles de NVIDIA Hopper, permettant ainsi de multiplier par 10 les revenus.
Pour atteindre ces performances de pointe pour les modèles d’IA actuels les plus complexes, tels que les modèles à grande échelle MoE (mixture-of-experts), il est nécessaire de répartir (ou désagréger) l’inférence sur plusieurs serveurs (nœuds) afin de servir des millions d’utilisateurs simultanés et de fournir des réponses plus rapides.
La plateforme logicielle NVIDIA Dynamo libère ces puissantes capacités multi-nœuds pour la production, ce qui permet aux entreprises d’atteindre les mêmes performances et la même efficacité primées dans leurs environnements cloud existants. Poursuivez votre lecture pour découvrir comment le passage à l’inférence multi-nœuds stimule les performances, et comment les plateformes cloud mettent cette technologie en œuvre.
Exploiter l’inférence désagrégée pour des performances optimisées
Pour les modèles d’IA qui s’intègrent sur un seul GPU ou un seul serveur, les développeurs exécutent souvent de nombreuses répliques du modèle en parallèle sur plusieurs nœuds pour obtenir un rendement élevé. Dans un article récent, Russ Fellows, analyste principal chez Signal65, a montré que cette approche a permis de réaliser un rendement agrégé record de l’industrie de 1,1 million de jetons par seconde avec 72 GPU NVIDIA Blackwell Ultra.
L’utilisation d’une technique appelée service désagrégé permet d’améliorer encore les performances et l’efficacité lors de la mise à l’échelle de modèles d’IA pour servir de nombreux utilisateurs simultanés en temps réel, ou lors de la gestion de charges de travail exigeantes impliquant de longues séquences d’entrée.
Le service des modèles d’IA comporte deux phases : le traitement de l’invite d’entrée (prétraitement) et la génération de la sortie (décodage). Traditionnellement, ces deux phases s’exécutent sur le même GPU, ce qui peut entraîner des inefficacités et des goulets d’étranglement au niveau des ressources.
Le service désagrégé résout ce problème en distribuant intelligemment ces tâches vers des GPU optimisés. Cette approche garantit que chaque partie de la charge de travail s’exécute avec les techniques d’optimisation les mieux adaptées, maximisant ainsi les performances globales. Pour les grands raisonnements d’IA et les modèles MoE, tels que DeepSeek-R1, le service désagrégé est essentiel.
NVIDIA Dynamo permet de facilement déployer des fonctionnalités telles que le service désagrégé à l’échelle de la production sur des clusters de GPU.
Ce framework apporte déjà une valeur ajoutée.
Baseten, par exemple, a utilisé NVIDIA Dynamo pour multiplier par deux la vitesse de traitement des inférences pour la génération de code à contexte long et multiplier par 1,6 le débit, le tout sans coûts matériels supplémentaires. Ces gains de performances logiciels permettent aux fournisseurs d’IA de réduire considérablement les coûts de fabrication de l’intelligence.
Faire évoluer l’inférence désagrégée dans le Cloud
À l’instar de ce qui s’est passé pour l’entraînement à grande échelle de l’IA, Kubernetes, la norme industrielle en matière de gestion d’applications conteneurisées, occupe une position idéale pour étendre le service désagrégé à des dizaines, voire des centaines de nœuds pour les déploiements d’IA à l’échelle de l’entreprise.
Grâce à l’intégration de NVIDIA Dynamo dans les services Kubernetes gérés par tous les principaux fournisseurs de cloud, les clients peuvent désormais étendre l’inférence multi-nœuds à l’ensemble des systèmes NVIDIA Blackwell, y compris les GB200 et GB300 NVL72, avec les performances, la flexibilité et la fiabilité requises par les déploiements d’IA en entreprise.
- Amazon Web Services accélère l’inférence de l’IA générative pour ses clients avec NVIDIA Dynamo, et l’intégration avec Amazon EKS.
- Google Cloud propose un guide pour optimiser l’inférence des grands modèles de langage (LLM) à l’échelle de l’entreprise sur son hypercalculateur IA avec Dynamo.
- Microsoft Azure permet l’inférence des LLM multi-nœuds avec NVIDIA Dynamo et les GPU ND GB200-v6 sur le service Azure Kubernetes.
- Oracle Cloud Infrastructure (OCI) permet l’inférence de LLM sur multi-nœuds avec OCI Superclusters et NVIDIA Dynamo.
La volonté de permettre l’inférence multi-nœuds dépasse le cadre des hyperscalers.
Nebius, par exemple, conçoit son Cloud pour prendre en charge les charges de travail d’inférence à grande échelle, grâce à l’infrastructure de calcul accéléré de NVIDIA et en collaborant avec NVIDIA Dynamo en tant que partenaire de l’écosystème.
Simplifier l’inférence sur Kubernetes avec NVIDIA Grove dans NVIDIA Dynamo
L’inférence de l’IA désagrégée nécessite la coordination de nombreux composants spécialisés (prétraitement, décodage, routage etc..) ayant chacun des besoins différents. Le défi pour Kubernetes ne consiste plus à exécuter davantage de copies parallèles d’un modèle, mais plutôt à gérer habilement chacun de ces composants au sein d’un système cohérent et hautement performant.
NVIDIA Grove, une interface de programmation d’applications désormais disponible dans NVIDIA Dynamo, permet aux utilisateurs de fournir une seule spécification de haut niveau qui décrit l’ensemble de leur système d’inférence.
Par exemple, dans cette spécification unique, un utilisateur peut simplement déclarer ses besoins : « J’ai besoin de trois nœuds GPU pour le prétraitement et de six nœuds GPU pour le décodage, et j’ai besoin que tous les nœuds d’une seule réplique de modèle soient placés sur la même interconnexion à haute vitesse pour une réponse la plus rapide possible. »
À partir de cette spécification, Grove gère automatiquement toutes les coordinations complexes : mise à l’échelle des composants associés tout en conservant les ratios et les dépendances corrects, démarrage dans le bon ordre et placement stratégique dans le cluster pour une communication rapide et efficace. Découvrez comment démarrer avec NVIDIA Grove dans cette analyse technique approfondie.
À mesure que l’inférence de l’IA devient de plus en plus distribuée, le fait de combiner Kubernetes avec NVIDIA Dynamo et NVIDIA Grove simplifie la façon dont les développeurs créent et font évoluer des applications intelligentes.
Essayez la simulation IA à l’échelle de NVIDIA pour voir comment le matériel et les choix de déploiement affectent les performances, l’efficacité et l’expérience utilisateur. Si vous souhaitez approfondir le service désagrégé et en apprendre davantage sur la façon dont les systèmes Dynamo et NVIDIA GB200 NVL72 fonctionnent ensemble pour améliorer les performances d’inférence, lisez ce blog technique.
Pour recevoir des mises à jour mensuelles, inscrivez-vous à la newsletter NVIDIA Think SMART.