La plateforme NVIDIA Blackwell a été largement adoptée par les principaux fournisseurs de solutions d’inférence tels que Baseten, DeepInfra, Fireworks AI et Together AI pour réduire jusqu’à 10 fois le coût par jeton. La plateforme NVIDIA Blackwell Ultra consolide aujourd’hui cette dynamique en optimisant les performances des applications d’IA agentique.
Les agents d’IA et les assistants de codage entraînent une croissance explosive des requêtes d’IA liées à la programmation logicielle, qui sont passées de 11 % à environ 50 % l’année dernière, selon le rapport d’OpenRouter sur l’état de l’inférence. Ces applications nécessitent le plus faible niveau de latence possible pour assurer une réactivité en temps réel lors du traitement des workflows multi-étapes tout en maintenant un contexte long lors du raisonnement sur des bases entières de code
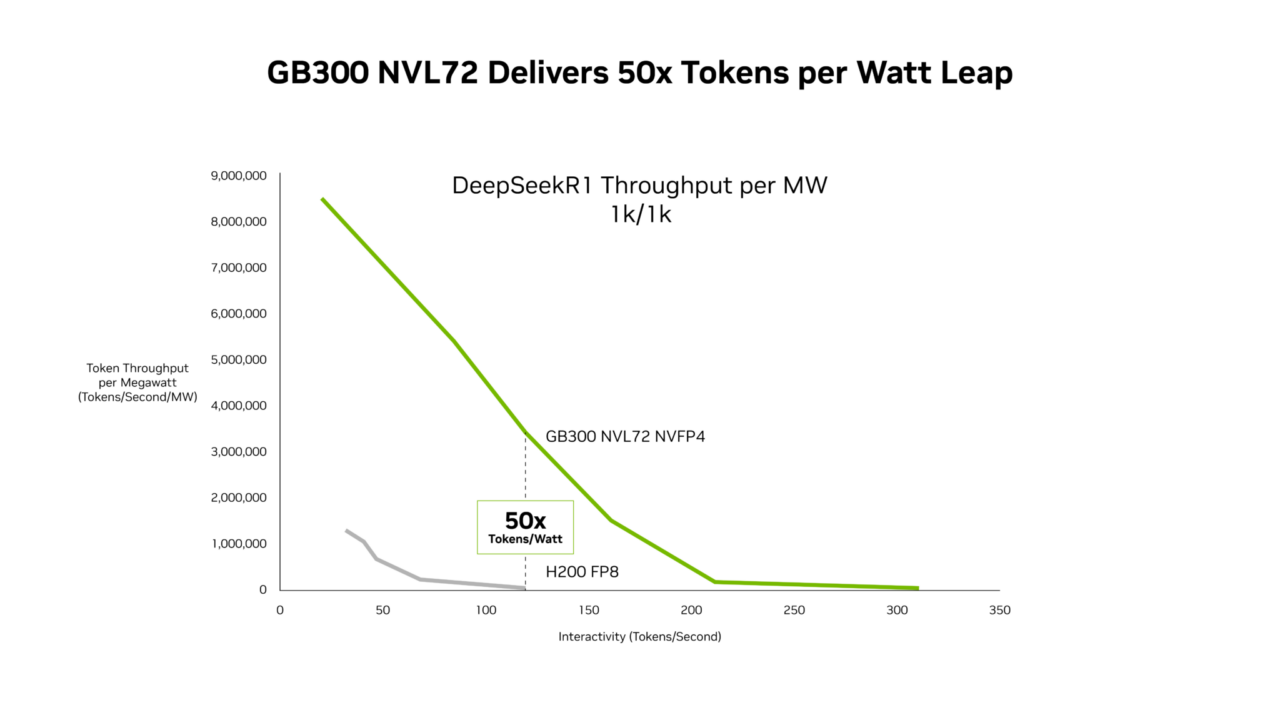
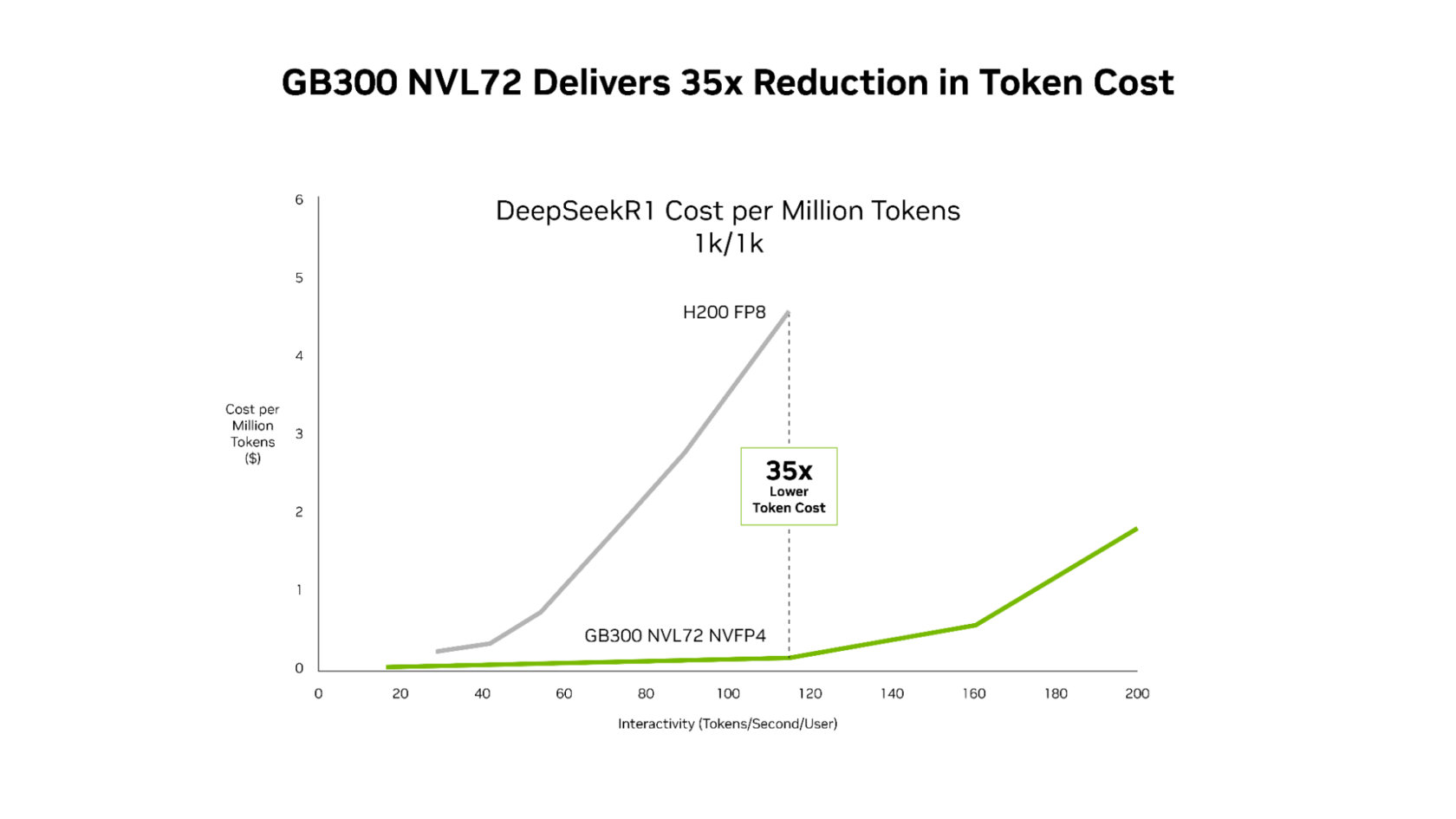
Les nouvelles données de performance InferenceX fournies par SemiAnalysis prouvent que la combinaison des optimisations logicielles de NVIDIA et de la plateforme NVIDIA Blackwell Ultra de nouvelle génération a permis de réaliser des avancées majeures sur ces deux fronts. Les systèmes NVIDIA GB300 NVL72 fournissent désormais un débit par mégawatt jusqu’à 50 fois supérieur, ce qui permet de diviser le coût par jeton par 35 par rapport à la plateforme NVIDIA Hopper.
En innovant dans le domaine des puces, de l’architecture système et des logiciels, la philosophie de co-conception extrême de NVIDIA contribue à accélérer les performances relatives aux charges de travail d’IA – du codage agentique aux assistants de codage interactif – tout en réduisant les coûts à grande échelle.

GB300 NVL72 fournit des performances jusqu’à 50 fois plus élevées pour les charges de travail à faible niveau de latence
Une analyse récente de Signal65 démontre que le système NVIDIA GB200 NVL72, qui se caractérise par une philosophie de co-conception matérielle et logicielle extrême, fournit plus de 10 fois plus de jetons par Watt, ce qui représente seulement un dixième du coût par jeton de la plateforme NVIDIA Hopper. Ces gains de performance phénoménaux ne cessent de croître à mesure que la pile sous-jacente s’améliore.
Les optimisations fournies en continu par les équipes de NVIDIA TensorRT-LLM, NVIDIA Dynamo, Mooncake et SGLang continuent d’augmenter considérablement le rendement de Blackwell NVL72 pour les inférences MoE (Mixture of Experts) avec toutes les cibles de latence. Par exemple, les améliorations apportées à la bibliothèque NVIDIA TensorRT-LLM ont permis de fournir des performances jusqu’à 5 fois supérieures sur GB200 pour les charges de travail à faible latence par rapport à celles obtenues il y a seulement quatre mois.
- Les noyaux GPU à hautes performances, optimisés pour proposer une efficacité optimale et une faible latence, permettent d’accélérer le rendement et d’exploiter le plein potentiel des importantes capacités de calcul de Blackwell.
- NVIDIA NVLink Symmetric Memory permet un accès direct à la mémoire GPU-vers-GPU pour une communication plus efficace.
- La fonctionnalité de lancement programmatique dépendant minimise les temps d’arrêt en lançant la phase de configuration du noyau suivant avant la fin de la phase précédente.
En s’appuyant sur ces avancées logicielles, le système GB300 NVL72 (qui intègre le GPU Blackwell Ultra) repousse les limites du débit par mégawatt avec des performances 50 fois plus rapides par rapport à la plateforme Hopper.
Ce gain de performance se traduit par une rentabilité supérieure, NVIDIA GB300 réduisant grandement les coûts par rapport à la plateforme Hopper sur l’ensemble du spectre de latence. La réduction la plus spectaculaire est observée à faible latence, niveau auquel les applications agentiques sont exécutées, avec un coût jusqu’à 35 fois plus faible par million de jetons par rapport à la plateforme Hopper.
Pour les charges de travail de codage agentique et d’assistants interactifs, pour lesquelles chaque milliseconde influe sur les performances des workflows multi-étapes, cette combinaison d’optimisations logicielles en continu et de solutions matérielles de nouvelle génération permet aux plateformes d’IA de mettre, en temps réel, des expériences interactives à la disposition d’un nombre considérablement plus important d’utilisateurs.
GB300 NVL72 offre une rentabilité supérieure pour les charges de travail à long contexte
Alors que les systèmes GB200 NVL72 et GB300 NVL72 fournissent une latence ultra-faible de manière efficace, les points forts du système GB300 NVL72 deviennent évidents dans les scénarios à long contexte. Pour les charges de travail avec 128 000 jetons en entrée et 8 000 jetons en sortie, telles que les assistants de codage d’IA raisonnant sur des bases de code, GB300 NVL72 propose un coût par jeton jusqu’à 1,5 fois inférieur par rapport à GB200 NVL72.
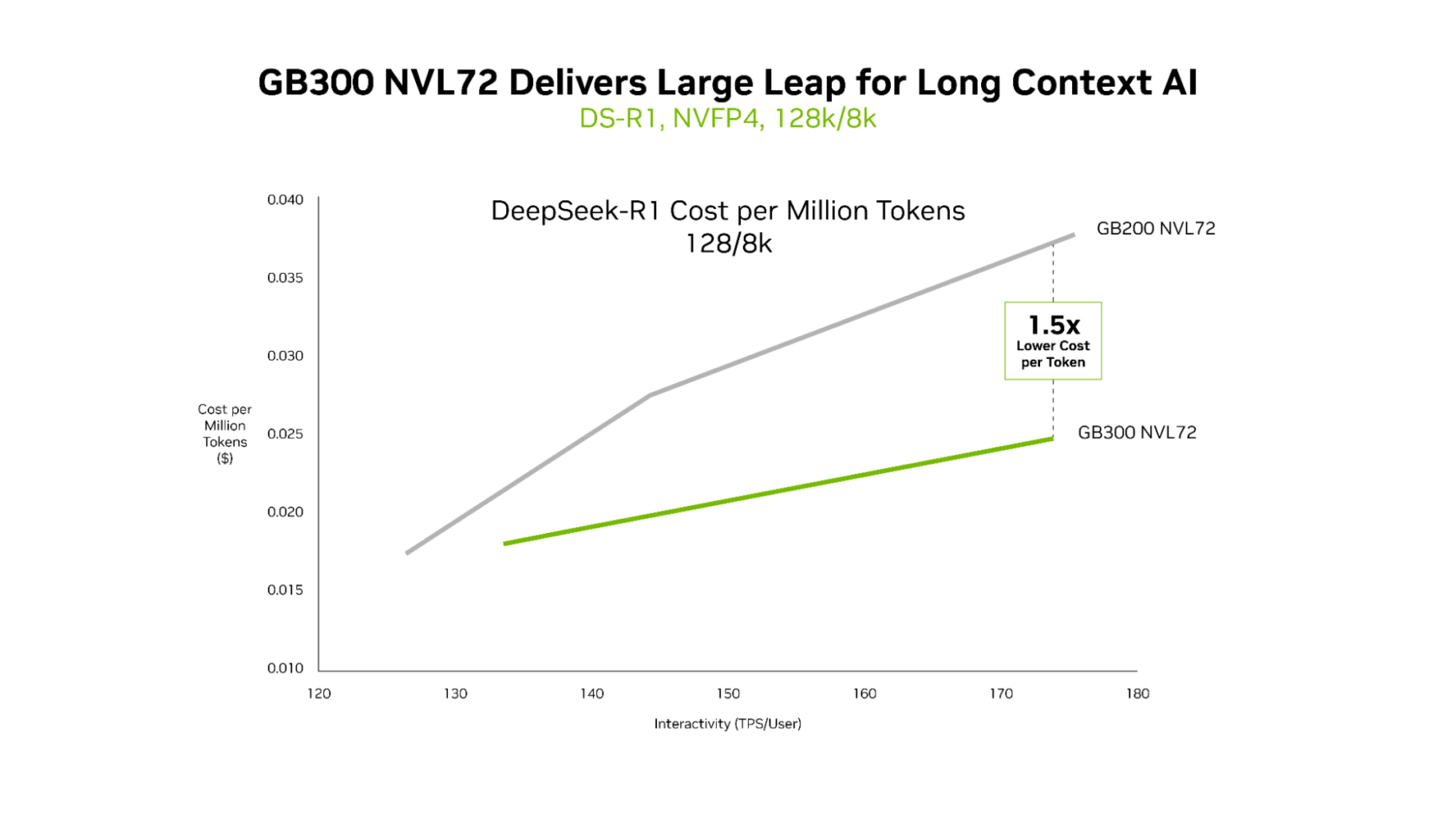
Le contexte s’accroît à mesure que l’agent transfère davantage de code. Cela permet au système de mieux comprendre la base de code, mais nécessite également beaucoup plus de capacités de calcul. Blackwell Ultra délivre des performances de calcul NVFP4 1,5 fois supérieures et un traitement de l’attention 2 fois plus rapide, ce qui permet à l’agent de comprendre efficacement des bases de code entières.
Infrastructure performante pour l’IA agentique
Les principaux fournisseurs de Cloud ainsi que les sociétés axées sur l’innovation grâce à une exploitation judicieuse de l’IA ont déjà déployé NVIDIA GB200 NVL72 à grande échelle et déploient également GB300 NVL72 en production. Microsoft, CoreWeave et OCI déploient GB300 NVL72 pour des cas d’utilisation à faible latence et à long contexte, tels que le codage agentique et les assistants de codage. En réduisant les coûts associés aux jetons, le système GB300 NVL72 permet à une nouvelle classe d’applications de raisonner sur des bases de code massives en temps réel.
« À mesure que l’inférence occupe une place centrale dans la production de l’IA, les performances à long contexte et l’efficacité des jetons deviennent absolument cruciales », explique Chen Goldberg, vice-présidente principale de l’ingénierie pour CoreWeave. « Le système Grace Blackwell NVL72 répond directement à ces défis, tandis que le Cloud d’IA de CoreWeave – incluant CKS et SUNK – a été conçu pour traduire les gains associés aux systèmes GB300, en s’appuyant sur le succès de GB200, de manière à offrir des performances prévisibles et une réduction significative des coûts. Il en résulte une meilleure économie des jetons et une inférence plus facilement utilisable pour les clients exécutant des charges de travail à grande échelle. »
NVIDIA Vera Rubin NVL72 va fournir des performances de nouvelle génération
À la suite du déploiement à grande échelle des systèmes basés sur la plateforme NVIDIA Blackwell, un programme d’optimisations logicielles en continu devrait permettre de continuer à proposer des gains de performance significatifs et des réductions de coûts supplémentaires sur l’ensemble de la base installée.
Et à l’avenir, la plateforme NVIDIA Rubin, qui combine six nouvelles puces pour alimenter un supercalculateur d’IA unique, devrait proposer une nouvelle série de gains de performance massifs. Pour l’inférence MoE, elle peut fournir un débit par mégawatt jusqu’à 10 fois supérieur à celui de Blackwell, ce qui représente un dixième du coût actuel par million de jetons. Enfin, pour la prochaine vague de modèles d’IA de pointe, Rubin sera en mesure d’entraîner de grands modèles MoE en utilisant seulement un quart du nombre de GPU par rapport à Blackwell.
Obtenez plus d’informations sur la plateforme NVIDIA Rubin et le système Vera Rubin NVL72.