
L’obtention d’informations diagnostiques dans le domaine de la santé. La création d’un dialogue naturel pour un personnage de jeu interactif. La résolution autonome d’un problème par un agent de service client. Chacune de ces interactions basées sur l’IA fait appel à la même unité d’intelligence, à savoir un jeton.
Pour faire évoluer efficacement ces interactions d’IA, chaque entreprise doit d’abord définir si elle peut se permettre d’investir dans la génération de jetons supplémentaires. Répondre à cette problématique nécessite de mettre en œuvre une meilleure tokénomique, qui vise essentiellement à réduire le coût de chaque jeton. Cette tendance nette de réduction des coûts se manifeste dans tous les secteurs. Des recherches récentes du MIT ont révélé que l’efficacité des infrastructures et des algorithmes pouvait réduire jusqu’à 10 fois les coûts annuels d’inférence pour l’obtention de performances de pointe.
Pour comprendre comment l’efficacité globale des infrastructures peut améliorer la tokénomique, on pourrait comparer cette situation à une presse d’impression à haute vitesse. Si la presse produit 10 fois plus de résultats avec un investissement progressif en encre, en énergie et dans la machine en elle-même, le coût d’impression de chaque page individuelle diminue. De même, les investissements dans les infrastructures d’IA peuvent entraîner une production de jetons bien plus élevée par rapport à l’augmentation des coûts, ce qui entraîne une réduction significative du coût par jeton.
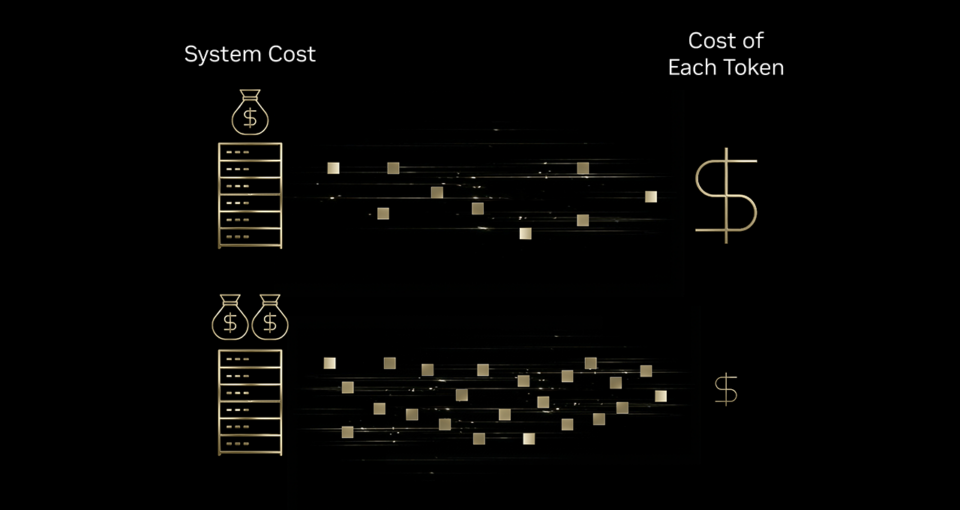
C’est pourquoi les principaux fournisseurs du secteur de l’inférence, tels que Baseten, DeepInfra, Fireworks AI et Together AI, tiennent à exploiter la plateforme NVIDIA Blackwell pour réduire jusqu’à 10 fois le coût par jeton par rapport à la plateforme NVIDIA Hopper.
Ces fournisseurs hébergent des modèles open source avancés, qui s’appuient désormais sur une intelligence de pointe pour fournir des résultats exceptionnels. En combinant une intelligence de pointe s’appuyant sur une philosophie open source avec l’approche de co-conception matérielle et logicielle extrême de NVIDIA Blackwell et leurs propres piles d’inférence soigneusement optimisées, ces fournisseurs permettent de réduire considérablement le coût des jetons pour les entreprises de tous les secteurs.
Santé : Baseten et Sully.ai divisent par 10 les coûts d’inférence de l’IA
Dans le domaine de la santé, les tâches fastidieuses et chronophages, telles que le codage médical, la documentation et la gestion des formulaires d’assurance, réduisent nettement le temps consacré par les médecins aux patients.
Sully.ai contribue à résoudre ce problème en développant des « employés d’IA » capables de gérer des tâches routinières telles que le codage médical et la prise de notes. À mesure que la plateforme de l’entreprise évoluait, ses modèles propriétaires à source fermée ont créé trois goulets d’étranglement : une latence imprévisible dans les workflows cliniques en temps réel, des coûts d’inférence qui évoluaient plus rapidement que les revenus, et un contrôle insuffisant sur la qualité et la mise à jour des modèles.
Pour surmonter ces goulets d’étranglement, Sully.ai utilise l’API de modèles de Baseten, qui permet de déployer des modèles open source tels que gpt-oss-120b sur des GPU NVIDIA Blackwell. Baseten a utilisé le format de données NVFP4 à faible précision, la bibliothèque NVIDIA TensorRT-LLM et le framework d’inférence NVIDIA Dynamo pour fournir une inférence optimisée. L’entreprise a choisi la plateforme NVIDIA Blackwell pour exécuter son API de modèles après avoir constaté un débit par dollar jusqu’à 2,5 fois supérieur à celui de la plateforme NVIDIA Hopper.
Les coûts d’inférence de Sully.ai ont ainsi chuté de 90 %, ce qui représente une réduction par 10 par rapport à l’implémentation précédente en source fermée, tandis que les délais de réponse se sont améliorés de 65 % pour les workflows critiques dans des domaines tels que la génération de notes médicales. L’entreprise a ainsi permis aux médecins d’économiser plus de 30 millions de minutes, un temps auparavant consacré à la saisie de données et à d’autres tâches manuelles.
Jeux vidéo : DeepInfra et Latitude divisent par 4 le coût par jeton
Latitude façonne l’avenir des jeux vidéo reposant sur l’IA native avec son jeu d’aventure narratif AI Dungeon et Voyage, sa nouvelle plateforme de jeu de rôle basée sur l’IA via laquelle les joueurs peuvent créer du contenu ou évoluer dans des mondes avec la liberté de choisir n’importe quelle action et de développer leur propre histoire.
La plateforme de l’entreprise utilise des grands modèles de langage (LLM) pour répondre aux actions des joueurs, ce qui implique des défis considérables en matière de mise à l’échelle, car chaque action d’un joueur déclenche une requête d’inférence. Les coûts évoluent avec l’engagement, et les délais de réponse doivent être suffisamment courts pour garantir une expérience fluide.

Latitude exécute de grands modèles open source sur la plateforme d’inférence de DeepInfra basée sur des GPU NVIDIA Blackwell et sur TensorRT-LLM. Pour un modèle Mixture of Experts (MoE) à grande échelle, DeepInfra a par exemple réduit le coût global pour la génération d’un million de jetons de 20 cents sur la plateforme NVIDIA Hopper à 10 cents sur Blackwell. Le passage au format NVFP4 natif à précision moins importante de Blackwell a permis de réduire ce coût à seulement 5 cents (soit une réduction par 4 du coût par jeton) tout en préservant le niveau de précision auquel les clients s’attendent.
L’exécution de ces modèles MoE à grande échelle sur la plateforme alimentée par Blackwell de DeepInfra permet à Latitude de fournir des réponses rapides et fiables de manière rentable. La plateforme d’inférence de DeepInfra fournit ces performances tout en gérant de manière fiable les pics de trafic, ce qui permet à Latitude de déployer des modèles plus performants sans se résoudre à compromettre l’expérience des joueurs.
Chat agentique : Fireworks AI et Sentient Foundation réduisent les coûts de l’IA jusqu’à 50 %
Sentient Labs œuvre à réunir les développeurs d’IA pour créer de puissants systèmes d’IA de raisonnement qui adoptent tous une approche open source. L’objectif consiste à accélérer l’IA pour résoudre des problèmes de raisonnement toujours plus difficiles grâce à des recherches dans les domaines de l’autonomie sécurisée, de l’architecture agentique et de l’apprentissage continu.
La première application de la société, baptisée Sentient Chat, orchestre des workflows multi-agents complexes et intègre plus d’une douzaine d’agents d’IA spécialisés issus de la communauté. C’est pour cette raison que Sentient Chat requiert d’énormes capacités de calcul, car une seule requête d’utilisateur peut déclencher une cascade d’interactions autonomes qui entraînent généralement des frais d’infrastructure relativement coûteux.
Pour gérer cette échelle de performance et cette complexité élevée, Sentient utilise la plateforme d’inférence de Fireworks AI basée sur NVIDIA Blackwell. Grâce à la pile d’inférence optimisée par Blackwell de Fireworks, Sentient a amélioré de 25 à 50 % sa rentabilité par rapport à son précédent déploiement logiciel basé sur Hopper.
L’augmentation du débit par GPU a permis à l’entreprise de soutenir nettement plus d’utilisateurs en simultané sans hausse des coûts. L’évolutivité de la plateforme a permis le lancement viral de 1,8 million d’utilisateurs sur liste d’attente en 24 heures et le traitement de 5,6 millions de requêtes en une semaine seulement, tout en se caractérisant par une latence faible et constante.
Service client : Together AI et Decagon divisent les coûts par 6
Les appels au service client avec l’IA vocale se soldent souvent par une certaine frustration, car même un léger retard dans les réponses peut amener les utilisateurs à couper la parole à l’agent, à raccrocher ou à perdre confiance.
Decagon est une société qui conçoit des agents d’IA pour l’assistance client d’entreprise, la voix basée sur l’IA étant son canal le plus exigeant. Decagon avait besoin d’une infrastructure capable de fournir des réponses en moins d’une seconde sous des charges de trafic imprévisibles, avec une tokénomique prenant en charge des déploiements vocaux 24 h/24 et 7 j/7.

Together AI exécute ses processus d’inférence de production pour la pile vocale multi-modèles de Decagon sur des processeurs graphiques NVIDIA Blackwell. Les deux entreprises ont collaboré pour parvenir à plusieurs optimisations-clés : le décodage spéculatif qui permet de mettre en œuvre des modèles plus petits pour générer des réponses plus rapides tandis qu’un modèle plus grand vérifie la précision en arrière-plan ; la mise en cache des éléments de conversation répétés pour accélérer les réponses, et ; la mise à l’échelle automatique pour gérer les pics de trafic sans dégrader les performances.
Decagon a enregistré des temps de réponse inférieurs à 400 millisecondes, même pour le traitement de milliers de jetons par requête. Le coût par requête, qui représente le coût total pour effectuer une interaction vocale, a été divisé par 6 par rapport à l’utilisation de modèles propriétaires à source fermée. Cette performance historique a été réalisée grâce à la combinaison de l’approche multi-modèles de Decagon (avec le recours à certains modèles open source et à d’autres entraînés en interne sur des GPU de NVIDIA), de l’approche d’extreme codesign sur laquelle repose NVIDIA Blackwell et de la pile pour l’inférence spécialement optimisée de Together.
Optimisation de la tokénomique grâce à à l’extrême codesign
Les économies considérables réalisées dans les domaines de la santé, des jeux vidéo et du service client sont dues à l’efficacité de l’architecture NVIDIA Blackwell. Le système NVIDIA GB200 NVL72 amplifie davantage cet impact en offrant une réduction révolutionnaire de 10 fois du coût par jeton pour les modèles MoE de raisonnement par rapport à NVIDIA Hopper.
L’ extrême codesign de NVIDIA à chaque couche de la pile – notamment en matière de calcul, de mise en réseau et de logiciels – ainsi que son vaste écosystème de partenaires permettent de réduire considérablement le coût par jeton à grande échelle.
Cette dynamique se poursuit avec la plateforme NVIDIA Rubin, qui intègre six nouvelles puces dans un seul supercalculateur d’IA pour fournir des performances 10 fois supérieures et un coût de jeton 10 fois inférieur par rapport à Blackwell.
Découvrez la plateforme d’inférence Full-Stack de NVIDIA et inscrivez-vous aux sessions de la NVIDIA GTC 2026 sur la tokénomique pour les inférences d’IA si vous souhaitez en savoir plus sur la façon dont cette plateforme contribue à améliorer la tokénomique dans le domaine des inférences d’IA.