
Les modèles ouverts stimulent une nouvelle vague d’IA sur les appareils, étendant l’innovation au-delà du Cloud pour inclure les appareils du quotidien. À mesure que ces modèles progressent, leur valeur dépend de plus en plus de l’accès à un contexte local en temps réel pour transformer des informations significatives en actions.
Conçus pour cette évolution, les derniers ajouts de Google à la gamme Gemma 4 intègrent une classe de modèles compacts, rapides et polyvalents, conçus pour une exécution locale efficace sur une large gamme d’appareils.
Google et NVIDIA ont collaboré pour optimiser Gemma 4 pour les GPU NVIDIA, permettant d’obtenir des performances efficaces sur une gamme complète de systèmes, des déploiements de Data Centers aux PC et stations de travail alimentés par NVIDIA RTX, en passant par le supercalculateur d’IA personnel NVIDIA DGX Spark et les modules d’IA à l’Edge NVIDIA Jetson Orin Nano.
Gemma 4 : modèles compacts optimisés pour les GPU NVIDIA
Les derniers ajouts à la gamme de modèles ouverts Gemma 4 — qui inclut les variantes E2B, E4B, 26B et 31B — sont conçus pour un déploiement efficace, des appareils à l’Edge aux GPU à haute performance.
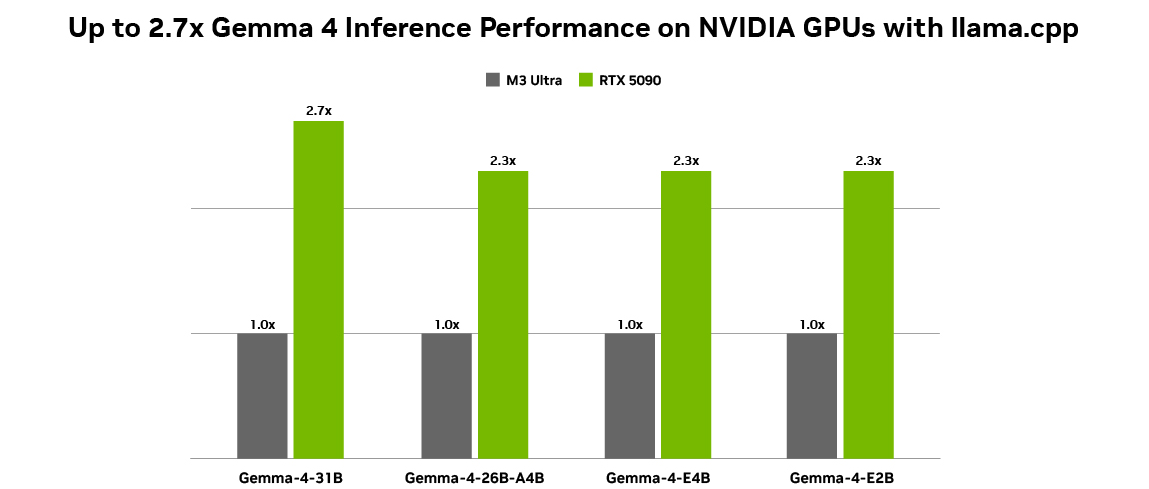
Cette nouvelle génération de modèles compacts prend en charge un ensemble de tâches, notamment :
- Raisonnement : performances élevées pour les tâches de résolution de problèmes complexes.
- Codage : génération de code et débogage pour les workflows de développeurs.
- Agents : prise en charge native de l’utilisation d’outils structurés (appel de fonctions).
- Fonctionnalités de vision, vidéo et audio : permet des interactions multimodales riches pour la reconnaissance d’objets, la reconnaissance vocale automatisée et l’analyse intelligente de documents ou de vidéos.
- Entrée multimodale intercalée : mélangez du texte et des images dans n’importe quel ordre en une seule invite.
- Multilingue : prise en charge native de plus de 35 langues, pré-entraînée sur plus de 140 langues.
Les modèles E2B et E4B sont conçus pour une inférence ultra-efficace à faible latence à l’Edge, s’exécutant complètement hors ligne avec une latence quasi nulle sur de nombreux appareils, y compris les modules Jetson Nano.
Les modèles 26B et 31B sont conçus pour les workflows de raisonnement haute performance et axés sur les développeurs, ce qui les rend particulièrement adaptés à l’IA agentique. Optimisés pour fournir un raisonnement de pointe et accessible, ces modèles s’exécutent efficacement sur les GPU NVIDIA RTX et DGX Spark, qui alimentent les environnements de développement, les assistants de codage et les workflows basés sur des agents.
Alors que l’IA agentique locale continue de prendre en ampleur, des applications telles que OpenClaw permettent de disposer d’assistants d’IA toujours actifs sur les PC RTX, les stations de travail et DGX Spark. Les derniers modèles Gemma 4 sont compatibles avec OpenClaw, qui permettent aux utilisateurs de créer des agents locaux à haut rendement exploitant le contexte de leurs fichiers personnels, d’applications et de workflows pour automatiser des tâches. Découvrez comment exécuter OpenClaw gratuitement sur des GPU RTX et DGX Spark ou en utilisant le DGX Spark OpenClaw Playbook.
Consultez l’article de Google DeepMind pour en savoir plus sur les nouveautés de la gamme Gemma 4 .
Lancement de Gemma 4 sur les GPU RTX et DGX Spark
NVIDIA a collaboré avec Ollama et llama.cpp pour fournir la meilleure expérience de déploiement local pour chacun des modèles Gemma 4.
Pour utiliser Gemma 4 en local, les utilisateurs peuvent télécharger Ollama pour exécuter les modèles Gemma 4 ou installer llama.cpp et l’associer au point de contrôle Gemma 4 GGUF Hugging Face. En outre, Unsloth fournit une prise en charge dès le premier jour avec des modèles optimisés et quantifiés pour un réglage fin et un déploiement local efficaces via Unsloth Studio. Commencez l’exécution et l’ajustement de Gemma 4 dans Unsloth Studio dès aujourd’hui.
L’exécution de modèles ouverts tels que la gamme Gemma 4 sur les GPU de NVIDIA permet d’atteindre des performances optimales, car les cœurs Tensor de NVIDIA accélèrent les charges de travail d’inférence d’IA pour fournir un débit plus élevé et une latence plus faible pour l’exécution locale. De plus, la pile logicielle CUDA garantit une large compatibilité avec les principaux frameworks et outils, ce qui permet d’exécuter efficacement de nouveaux modèles dès le premier jour.
Cette combinaison permet à des modèles ouverts tels que Gemma 4 de s’adapter à une large gamme de systèmes, de Jetson Orin Nano à l’Edge aux PC RTX, aux stations de travail et à DGX Spark, sans nécessiter une optimisation approfondie.
Consultez le blog technique NVIDIA pour plus de détails sur la façon de démarrer avec Gemma 4 sur les GPU NVIDIA et pour en savoir plus sur le travail de NVIDIA sur les modèles ouverts.
#ICYMI : dernières mises à jour pour les PC d’IA RTX
✨ Découvrez les articles de RTX AI Garage pour suivre une série d’annonces sur l’IA agentique issues de la NVIDIA GTC, notamment de nouveaux modèles ouverts pour les agents locaux. Ces modèles incluent NVIDIA Nemotron 3 Nano 4B et Nemotron 3 Super 120B, et des optimisations pour Qwen 3.5 et Mistral Small 4.
NVIDIA a récemment présenté NVIDIA NemoClaw, une pile open source qui optimise les expériences OpenClaw sur les appareils NVIDIA en augmentant la sécurité et en prenant en charge les modèles locaux.
🚀 Accomplish.ai a annoncé Accomplish FREE, une version gratuite de son agent d’IA de bureau open source avec des modèles intégrés. Elle exploite les GPU NVIDIA pour exécuter des modèles Ope-Weight en local, tandis qu’un routeur hybride équilibre dynamiquement les charges de travail entre le matériel RTX local et le Cloud — permettant une exécution rapide, privée et sans configuration, sans nécessiter de clé d’interface de programmation d’application.
Suivez NVIDIA AI PC sur Facebook, Instagram, TikTok et X — et ne loupez aucune information en vous abonnant à la newsletter RTX AI PC.