
Dans l’IA d’entreprise, comprendre et travailler dans plusieurs langues n’est plus facultatif : il est essentiel pour répondre aux besoins des employés, des clients et des utilisateurs dans le monde entier.
La récupération d’informations multilingues, c’est-à-dire la capacité de rechercher, de traiter et de récupérer des connaissances dans toutes les langues, joue un rôle clé pour permettre à l’IA de fournir des sorties plus précises et pertinentes à l’échelle mondiale.
Les entreprises peuvent étendre leurs efforts d’IA générative en des systèmes précis et multilingues en utilisant NVIDIA NeMo Retriever en intégrant et en reclassant les microservices NVIDIA NIM, qui sont désormais disponibles dans le catalogue d’API NVIDIA. Ces modèles peuvent comprendre les informations dans un large éventail de langues et de formats, comme des documents, pour fournir des résultats précis et contextuels à grande échelle.
Avec NeMo Retriever, les entreprises peuvent maintenant :
- Extraire des connaissances à partir de divers grands ensembles de données grands et divers pour un contexte supplémentaire afin de fournir des réponses plus précises.
- Connecter de manière transparente l’IA générative aux données d’entreprise dans la plupart des principales langues mondiales pour élargir le public d’utilisateurs.
- Fournir des informations exploitables à plus grande échelle avec une efficacité de stockage de données 35 fois améliorée grâce à de nouvelles techniques comme la prise en charge de contexte de longue durée et la taille de l’intégration dynamique.
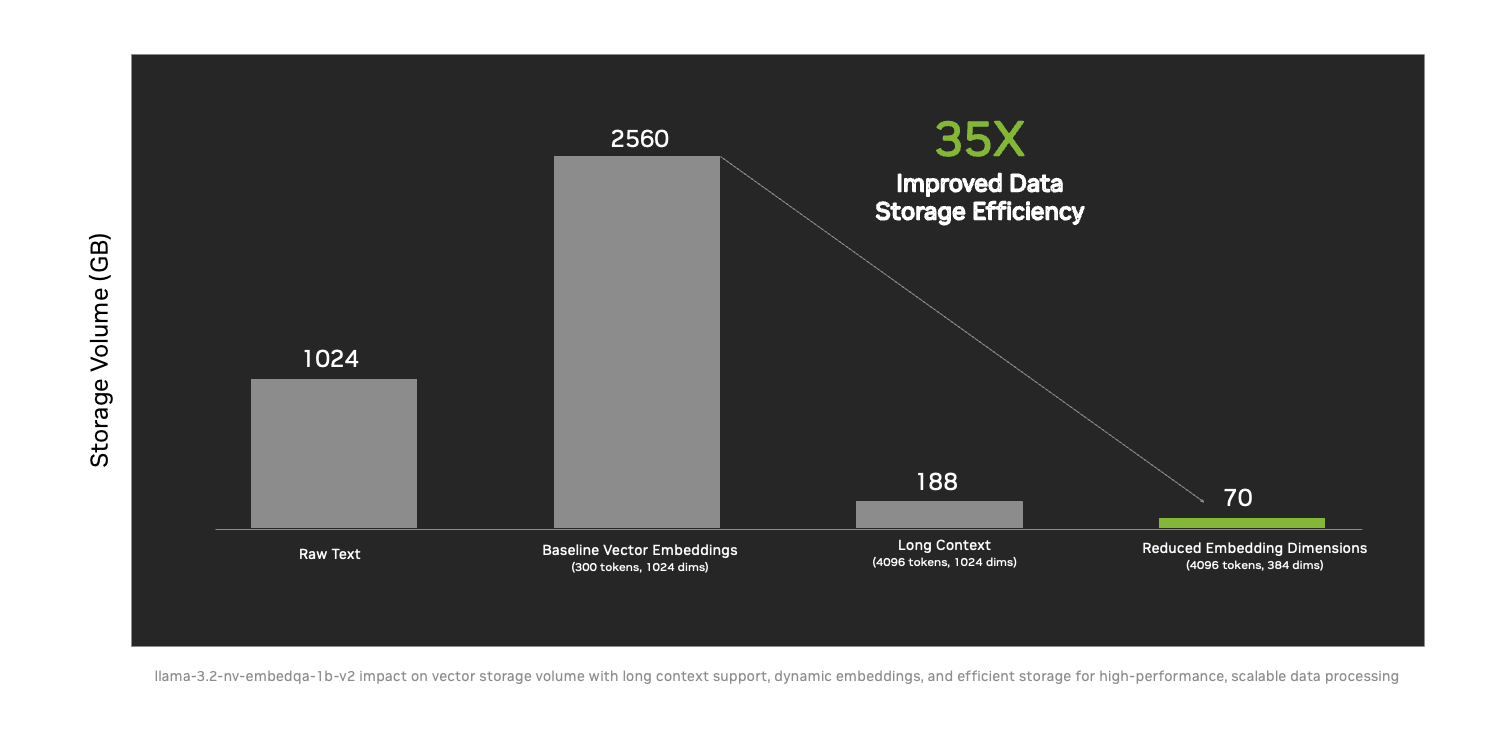
Les nouveaux microservices NeMo Retriever réduisent par 35 les besoins en volume de stockage, permettant aux entreprises de traiter plus d’informations à la fois et de s’adapter à de grandes bases de connaissances sur un seul serveur. Cela rend les solutions d’IA plus accessibles, rentables et plus faciles à mettre à l’échelle dans toutes les organisations. Les principaux partenaires de NVIDIA comme DataStax, Cohesity, Cloudera, Nutanix, SAP, VAST Data et WEKA adoptent déjà ces microservices pour aider les organisations de tous les secteurs à connecter en toute sécurité des modèles personnalisés à de grandes sources de données diverses. En utilisant des techniques de génération augmentée par récupération (RAG), NeMo Retriever permet aux systèmes d’IA d’accéder à des informations plus riches et plus pertinentes et de combler efficacement les écarts linguistiques et contextuels.
Wikidata accélère le traitement des données de 30 jours à moins de trois jours
En partenariat avec DataStax, Wikimedia a mis en œuvre NeMo Retriever pour intégrer de manière vectorielle le contenu de Wikipedia, desservant des milliards d’utilisateurs. L’intégration de vecteurs, ou « vectorisation », est un processus qui transforme les données en un format que l’IA peut traiter et comprendre pour extraire des informations et prendre des décisions intelligentes.
Wikimedia a utilisé les microservices NIM NeMo Retriever pour vectoriser plus de 10 millions d’entrées Wikidata en formats prêts pour l’IA en moins de trois jours, un processus qui prenait 30 jours. Cette accélération multipliée par 10 permet un accès évolutif et multilingue à l’un des plus grands graphiques de connaissances open source au monde. Ce projet révolutionnaire assure des mises à jour en temps réel pour des centaines de milliers d’entrées qui sont modifiées quotidiennement par des milliers de contributeurs, améliorant l’accessibilité mondiale pour les développeurs et les utilisateurs. Avec le modèle serverless d’Astra DB et les technologies NVIDIA AI, l’offre DataStax offre une latence proche de zéro et une évolutivité exceptionnelle pour répondre aux demandes dynamiques de la communauté Wikimedia.
DataStax utilise NVIDIA AI Blueprints et intègre les microservices NVIDIA NeMo Customizer, Curator, Evaluator et Guardrails dans le générateur de code LangFlow AI pour permettre à l’écosystème des développeurs d’optimiser les modèles et les pipelines d’IA pour leurs cas d’utilisation uniques et aider les entreprises à faire évoluer leurs applications d’IA.
L’IA inclusive en termes de langage stimule l’impact commercial mondial
NeMo Retriever aide les entreprises mondiales à surmonter les obstacles linguistiques et contextuels et à débloquer le potentiel de leurs données. En déployant des solutions d’IA robustes, les entreprises peuvent obtenir des résultats précis, évolutifs et à fort impact.
La plateforme et les partenaires en consulting de NVIDIA jouent un rôle essentiel pour s’assurer que les entreprises puissent adopter et intégrer efficacement les capacités d’IA générative, comme les nouveaux microservices NeMo Retriever. Ces partenaires aident à aligner les solutions d’IA aux besoins et aux ressources uniques d’une organisation, ce qui rend l’IA générative plus accessible et efficace. Ils comprennent :
- Cloudera prévoit d’étendre l’intégration de NVIDIA AI dans le service d’inférence Cloudera AI. Actuellement intégré à NVIDIA NIM, Cloudera AI Inference inclura NVIDIA NeMo Retriever pour améliorer la vitesse et la qualité des informations pour les cas d’utilisation multilingues.
- Cohesity a présenté le premier assistant de recherche conversationnel alimenté par l’IA générative du secteur qui utilise des données de sauvegarde pour fournir des réponses éclairées. Il utilise le microservice de reclassement NVIDIA NeMo Retriever pour améliorer la précision de la récupération et améliorer de manière significative la vitesse et la qualité des informations pour diverses applications.
- SAP utilise les capacités d’ancrage de NeMo Retriever pour ajouter du contexte à sa fonctionnalité de questions-réponses de copilote Joule et aux informations récupérées à partir de documents personnalisés.
- VAST Data déploie les microservices NeMo Retriever sur le VAST Data InsightEngine avec NVIDIA pour rendre les nouvelles données instantanément disponibles pour l’analyse. Cela accélère l’identification des informations commerciales en capturant et en organisant des informations en temps réel pour les décisions alimentées par l’IA.
- WEKA intègre son architecture WEKA AI RAG Reference Platform (WARRP) avec NVIDIA NIM et NeMo Retriever dans sa plateforme de données à faible latence pour fournir des solutions d’IA évolutives et multimodales, en traitant des centaines de milliers de jetons par seconde.
Briser les barrières linguistiques avec la récupération d’informations multilingues
La récupération d’informations multilingues est vitale pour l’IA en entreprise pour répondre aux demandes du monde réel. NeMo Retriever prend en charge une récupération de texte efficace et précise dans plusieurs langues et des ensembles de données multilingues. Il est conçu pour les cas d’utilisation d’entreprise comme la recherche, les réponses aux questions, le résumé et les systèmes de recommandation.
En outre, il répond à un défi important de l’IA en entreprise : la gestion de grands volumes de grands documents. Avec une prise en charge de contexte à long terme, les nouveaux microservices peuvent traiter de longs contrats ou des dossiers médicaux détaillés tout en maintenant la précision et la cohérence lors des interactions prolongées.
Ces capacités aident les entreprises à utiliser leurs données plus efficacement, en fournissant des résultats précis et fiables pour les employés, les clients et les utilisateurs tout en optimisant les ressources pour l’évolutivité. Les outils de récupération multilingues avancés comme NeMo Retriever peuvent rendre les systèmes d’IA plus adaptables, accessibles et impactants dans un secteur mondialisé.
Disponibilité
Les développeurs peuvent accéder aux microservices NeMo Retriever multilingues et à d’autres
microservices NIM pour la récupération d’informations, via le catalogue d’API NVIDIA ou une licence de développement NVIDIA AI Enterprise de 90 jours sans frais.
En savoir plus sur les nouveaux microservices NeMo Retriever et comment les utiliser pour créer des systèmes de récupération d’informations efficaces.