
- NVIDIA Blackwell a surpassé les nouveaux benchmarks SemiAnalysis InferenceMAX v1, offrant les meilleures performances et la meilleure efficacité globale.
- InferenceMax v1 est le premier benchmark indépendant à mesurer le coût total de calcul sur différents modèles et scénarios réels.
- Meilleur retour sur investissement : NVIDIA GB200 NVL72 offre une rentabilité inégalée pour les usines d’IA : un investissement de 5 millions de dollars génère 75 millions de dollars de revenus en jetons DSR1, soit un retour sur investissement 15 fois supérieur.
- Coût total de possession le plus bas : les optimisations logicielles de NVIDIA B200 permettent d’atteindre deux cents par million de jetons sur gpt-oss, soit un coût par jeton 5 fois inférieur en seulement 2 mois.
- Meilleur débit et meilleure interactivité : NVIDIA B200 donne le ton avec 60 000 jetons par seconde par GPU et 1 000 jetons par seconde par utilisateur sur gpt-oss avec la dernière pile NVIDIA TensorRT-LLM.
À mesure que l’IA passe de réponses uniques à un raisonnement complexe, la demande en matière d’inférence et l’économie qui la sous-tendent explosent.
Les nouveaux benchmarks indépendants InferenceMAX v1 sont les premiers à mesurer le coût total de calcul dans des scénarios réels. Les résultats ? La plateforme phare de NVIDIA, Blackwell, a dominé le terrain, en offrant des performances inégalées et la meilleure efficacité globale pour les usines d’IA.
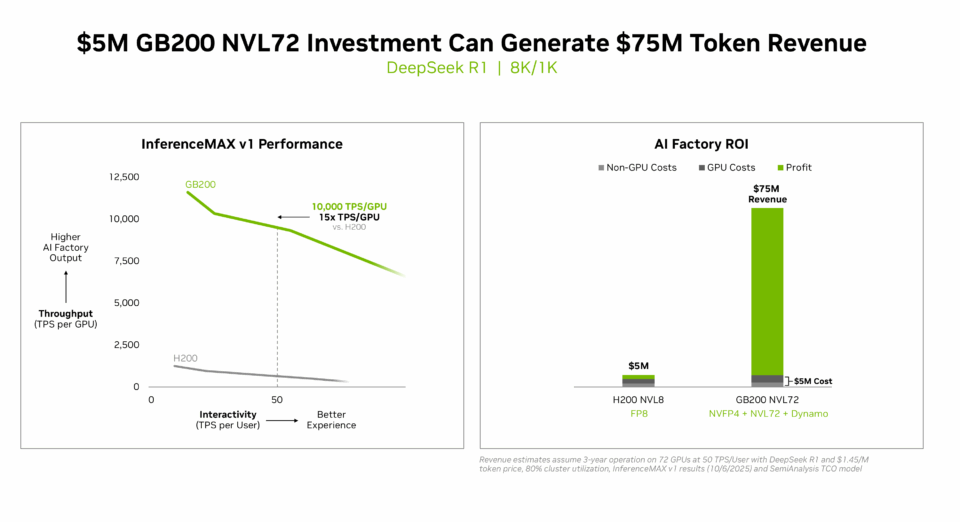
Un investissement de 5 millions de dollars dans un système GB200 NVL72 peut générer 75 millions de dollars en revenus de jetons. La nouvelle économie de l’inférence représente un retour sur investissement multiplié par 15.
L’inférence est un domaine dans lequel l’IA fournit quotidiennement de la valeur », a déclaré Ian Buck, vice-président de l’hyperscale et du HPC chez NVIDIA. « Ces résultats montrent que l’approche complète de NVIDIA offre aux clients les performances et l’efficacité dont ils ont besoin pour déployer l’IA à grande échelle.
Entrez dans InferenceMAX v1
InferenceMAX v1, un nouveau benchmark de SemiAnalysis publié lundi, est le dernier benchmark à souligner le leadership de Blackwell en matière d’inférence. Elle permet d’exécuter des modèles populaires sur les principales plateformes, de mesurer les performances dans une large gamme de cas d’utilisation et de publier des résultats que quiconque peut vérifier.
Pourquoi de tels benchmarks sont-ils importants ?
Parce que l’IA moderne ne se limite pas à la vitesse brute, mais aussi à l’efficacité et à l’économie à grande échelle. Lorsque les modèles passent de réponses uniques au raisonnement en plusieurs étapes et à l’utilisation d’outils, ils génèrent beaucoup plus de jetons par requête, ce qui augmente considérablement les demandes de calcul.
Les collaborations open source de NVIDIA avec OpenAI (gpt-oss 120B), Meta (Llama 3 70B) et DeepSeek AI (DeepSeek R1) mettent en évidence la façon dont les modèles basés sur la communauté font progresser le raisonnement et l’efficacité de pointe.
En partenariat avec ces principaux concepteurs de modèles et la communauté open source, NVIDIA garantit que les derniers modèles sont optimisés pour la plus grande infrastructure d’inférence d’IA au monde. Ces efforts reflètent un engagement plus large en faveur d’écosystèmes ouverts, au sein desquels l’innovation partagée accélère les progrès pour tous.
Des partenariats approfondis avec les communautés FlashInfer, SGLang et vLLM permettent d’améliorer en co-développement le noyau et l’exécution qui alimentent ces modèles à grande échelle.
L’innovation logicielle continue au cœur de l’inférence Blackwell
NVIDIA améliore en permanence les performances grâce à des optimisations de la co-conception matérielle et logicielle. Les performances initiales de gpt-oss-120b sur Blackwell B200 avec TensorRT-LLM étaient leaders sur le marché, mais les équipes de NVIDIA et la communauté ont considérablement optimisé TensorRT-LLM pour les LLM open source.
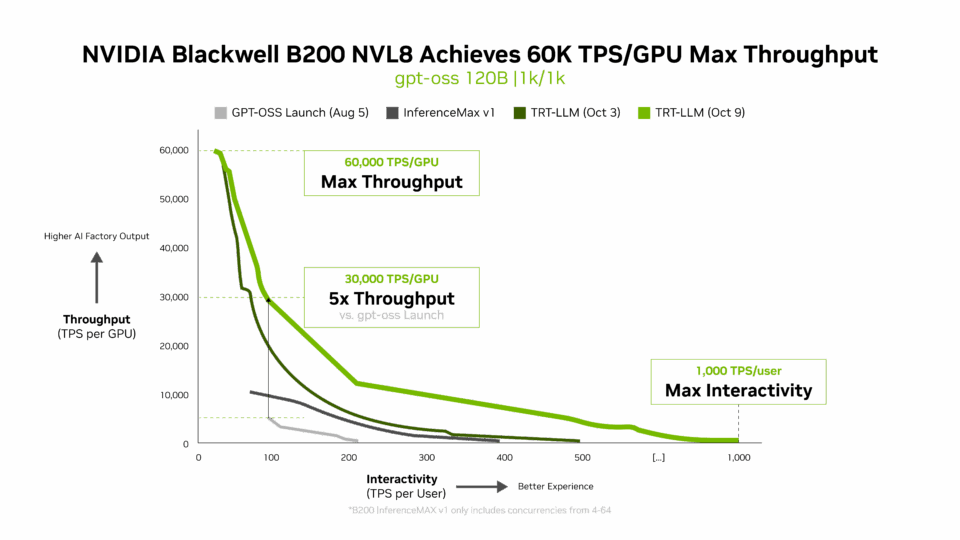
La dernière version de TensorRT-LLM 1.0 de NVIDIA constitue une avancée majeure dans la réalisation de grands modèles d’IA plus rapides et plus réactifs pour tous.
Grâce à des techniques de parallélisation avancées, elle exploite le système B200 et la bande passante bidirectionnelle de 1 800 Go/s de son commutateur NVIDIA NVLink Switch pour améliorer considérablement les performances du modèle gpt-oss-120b.
Mais l’innovation ne s’arrête pas là. Le modèle gpt-oss-120b-Eagle3 nouvellement publié introduit le décodage spéculatif, une méthode intelligente qui prédit plusieurs jetons à la fois.
Cette approche réduit le retard et permet d’obtenir des résultats encore plus rapides, en triplant le rendement à 100 TPS par utilisateur, ce qui permet d’augmenter la vitesse par GPU de 10 000 à 30 000 jetons.
Pour les modèles d’IA denses tels que Llama 3.3 70B, qui nécessitent d’importantes ressources de calcul en raison de leur grand nombre de paramètres et du fait que tous les paramètres sont utilisés simultanément pendant l’inférence, NVIDIA Blackwell B200 établit une nouvelle norme de performances dans les benchmarks InferenceMAX v1.
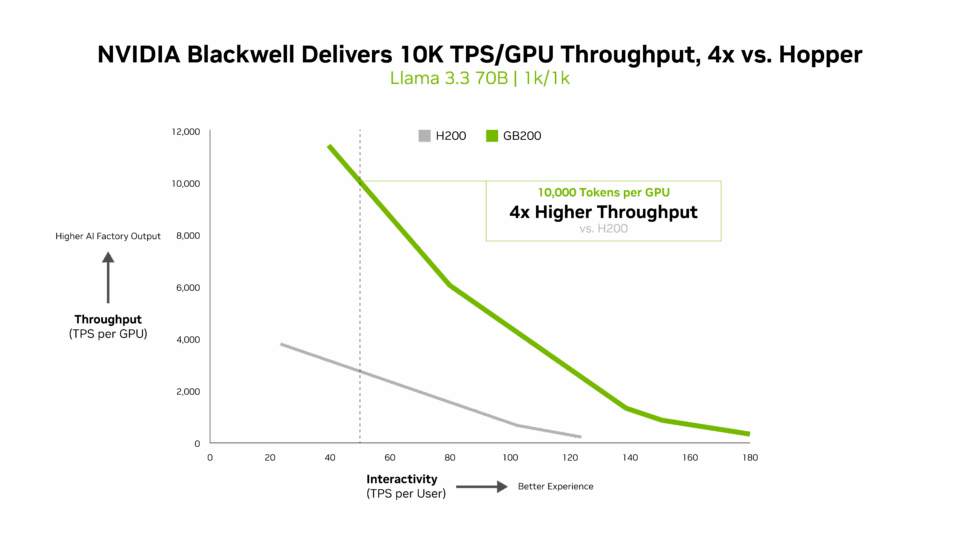
Blackwell fournit plus de 10 000 TPS par GPU pour 50 TPS par interactivité utilisateur, soit un rendement par GPU quatre fois supérieur à celui du Hopper H200.
L’efficacité des performances crée de la valeur
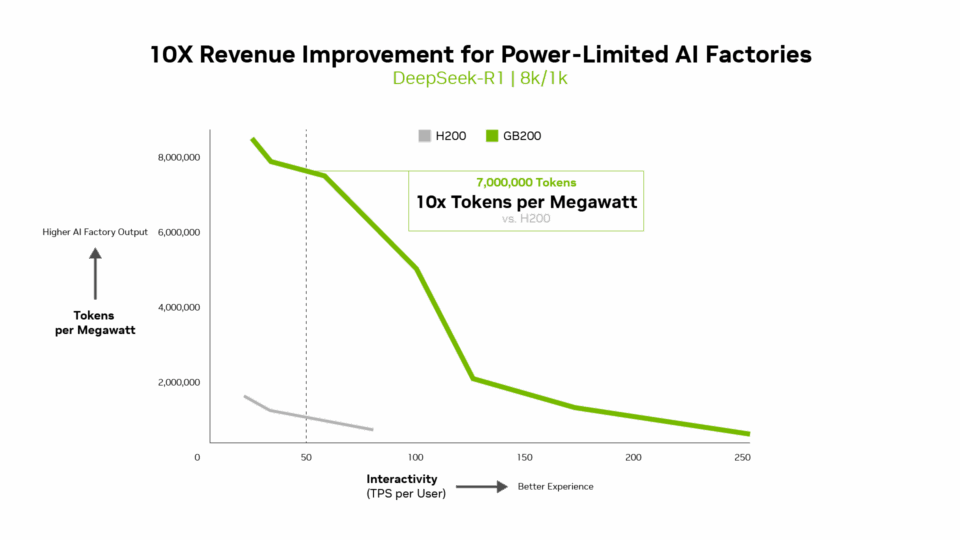
Des métriques telles que les jetons par watt, le coût par million de jetons et les jetons par seconde par utilisateur (TPS/utilisateur) sont tout aussi importantes que le débit. En fait, pour les usines d’IA à consommation limitée, Blackwell fournit un rendement par mégawatt 10 fois plus élevé que la génération précédente, ce qui se traduit par des revenus de jetons plus élevés.
Le coût par jeton est essentiel pour évaluer l’efficacité des modèles d’IA et a un impact direct sur les dépenses d’exploitation. L’architecture Blackwell a permis de réduire considérablement le coût par million de jetons de 15 fois par rapport à la génération précédente, ce qui a permis de réaliser des économies substantielles et de favoriser un déploiement et une innovation plus large de l’IA.
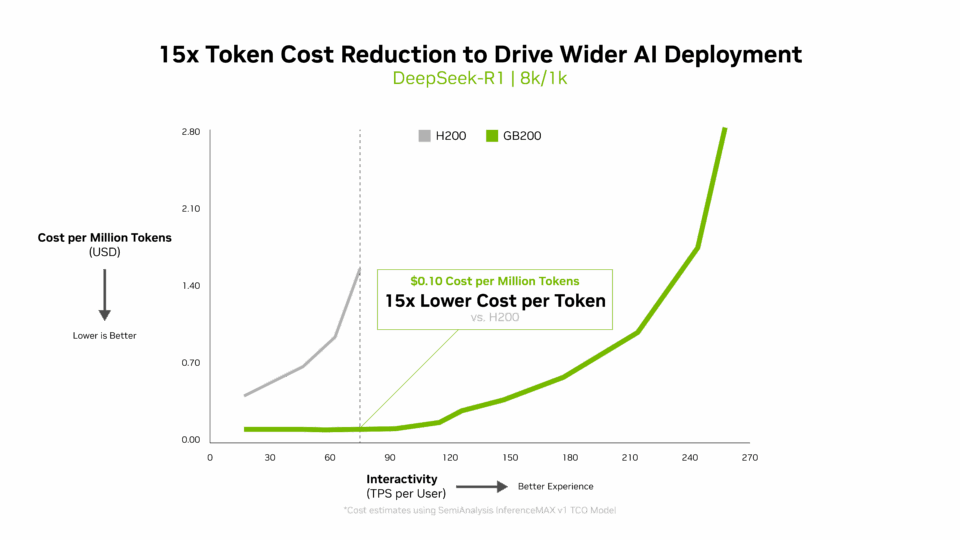
Performances multidimensionnelles
InferenceMAX utilise la frontière de Pareto, une courbe qui montre les meilleurs compromis entre différents facteurs, tels que le rendement des centres de données et la réactivité, pour cartographier les performances.
Mais il s’agit de bien plus que d’un graphique. Il reflète la façon dont NVIDIA Blackwell équilibre toute la gamme des priorités de production : coût, efficacité énergétique, rendement et réactivité. Cet équilibre permet d’obtenir le retour sur investissement le plus élevé pour les charges de travail réelles.
Les systèmes qui optimisent un seul mode ou scénario peuvent présenter des performances maximales lorsqu’ils sont isolés, mais leur économie ne se développe pas. La conception full-stack de Blackwell offre efficacité et valeur là où elles sont le plus importantes : en production.
Pour en savoir plus sur la façon dont ces courbes sont construites et sur leur importance pour le coût total de possession et la planification des accords de niveau de service, consultez notre étude technique approfondie pour obtenir des graphiques complets et une méthodologie.
Qu’est-ce qui le rend possible ?
Le leadership de Blackwell provient de la co-conception extrême du matériel et des logiciels. Il s’agit d’une architecture Full-Stack conçue pour la vitesse, l’efficacité et l’évolutivité :
- Les caractéristiques de l’architecture Blackwell incluent :
- Le format à faible précision NVFP4 pour une efficacité sans perte d’exactitude
- La technologie NVIDIA NVLink de cinquième génération qui connecte 72 GPU Blackwell pour agir comme un seul GPU géant.
- NVLink Switch qui permet une concurrence élevée grâce à des algorithmes d’attention avancés pour les tenseurs, les experts et le parallèle des données.
- Cadence matérielle annuelle et optimisation logicielle continue : NVIDIA a plus que doublé les performances de Blackwell depuis son lancement en utilisant uniquement un logiciel
- NVIDIA TensorRT-LLM, NVIDIA Dynamo, SGLang et vLLM, des frameworks d’inférence open source optimisés pour des performances maximales
- Un vaste écosystème, avec des centaines de millions de GPU installés, sept millions de développeurs CUDA et des contributions à plus de 1 000 projets open source
Une perspective globale
l’IA passe des projets pilotes aux usines d’IA, une infrastructure qui fabrique de l’intelligence en transformant les données en jetons et en décisions en temps réel.
Les benchmarks ouverts et fréquemment mis à jour aident les équipes à faire des choix de plateforme éclairés, à ajuster le coût par jeton, les accords de niveau de service de latence et l’utilisation avec des charges de travail changeantes.
Le framework Think SMART de NVIDIA aide les entreprises à naviguer dans cette transition en mettant en avant la façon dont la plateforme d’inférence full-stack de NVIDIA fournit un retour sur investissement réel et transforme les performances en profits.