L’intelligence artificielle, comme toute technologie innovante, est un projet évolutif : ses capacités et son impact sur la société ne cessent de croître. Les initiatives sérieuses en IA tiennent compte des effets réels que l’IA peut avoir sur les personnes et la société, et visent à orienter ce pouvoir de manière responsable pour apporter des changements positifs.
Qu’est-ce que l’IA fiable ?
L’IA fiable est une approche du développement de l’IA qui donne la priorité à la sécurité et à la transparence pour les individus qui interagissent avec elle. Les développeurs d’IA fiable comprennent qu’aucun modèle n’est parfait et prennent des mesures pour aider les clients et le public à comprendre comment la technologie a été créée, ses cas d’utilisation prévus et ses limites.
En plus de respecter les lois sur la protection de la confidentialité et des clients, les modèles d’IA fiables sont soumis à des tests vérifiant que leur sûreté, leur innocuité, et l’atténuation des biais indésirables sont satisfaisants. Ils sont également transparents, fournissant des informations telles que des bancs d’essai de leur précision ou une description du jeu de données utilisé pour leur entraînement, à l’égard des différents publics, notamment les autorités de réglementation, les développeurs et les consommateurs.
Principes de l’IA fiable
Le développement de l’IA de bout en bout de NVIDIA s’appuie sur des principes d’IA fiable. Ces principes ont un objectif simple : favoriser la fiabilité et la transparence en matière d’IA et soutenir le travail des partenaires, des clients et des développeurs.
Confidentialité : respecter la réglementation, protéger les données
L’IA est souvent décrite comme grande consommatrice de données. Les algorithmes fournissent souvent des résultats plus précis lorsqu’ils sont entraînés avec davantage de données.
Mais les données doivent venir de quelque part. Pour développer une IA fiable, il est essentiel de tenir compte non seulement des données disponibles qui sont légalement utilisables, mais aussi des données qu’il est socialement responsable d’utiliser.
Les développeurs de modèles d’IA qui s’appuient sur des données comme l’image, la voix, le travail artistique ou les données médicales d’une personne doivent évaluer si la personne concernée a donné son consentement de manière appropriée pour que ses informations personnelles soient utilisées à bon escient.
Pour les institutions comme les hôpitaux et les banques, créer des modèles d’IA implique de trouver un juste équilibre entre préserver la confidentialité des données des patients ou des clients et entraîner un algorithme robuste. NVIDIA a créé une technologie qui permet un apprentissage fédéré, dans lequel les chercheurs développent des modèles d’IA entraînés sur des données provenant de diverses institutions, sans que les informations confidentielles quittent les serveurs privés de l’entreprise.
Les systèmes NVIDIA DGX et le logiciel NVIDIA FLARE ont permis de réaliser plusieurs projets d’apprentissage fédéré dans les secteurs de la santé et des services financiers, en facilitant une collaboration sécurisée entre plusieurs fournisseurs de données sur des modèles d’IA plus précis et généralisables dans le cadre de l’analyse d’images médicales et de la détection de la fraude.
Sûreté et innocuité : éviter les dommages involontaires et les menaces malveillantes
Une fois déployés, les systèmes d’IA ont un impact réel et il est donc essentiel qu’ils fonctionnent comme prévu pour préserver la sécurité des utilisateurs.
La liberté d’utiliser des algorithmes d’IA disponibles au public ouvre d’immenses possibilités pour des applications bénéfiques, mais signifie également que cette technologie peut être utilisée à des fins imprévues.
Pour contribuer à atténuer les risques, NVIDIA NeMo Guardrails maintient les modèles de langage d’IA sur les rails en permettant aux développeurs d’entreprise de fixer des limites à leurs applications. Les garde-fous thématiques veillent à ce que les chatbots restent fidèles à des sujets spécifiques. Les garde-fous de sécurité fixent des limites au langage et aux sources de données que les applications utilisent dans leurs réponses. Les garde-fous de sécurité cherchent à empêcher l’utilisation malveillante d’un grand modèle de langage relié à des applications tierces ou à des interfaces de programmation d’applications.
NVIDIA Research collabore avec le programme SemaFor de DARPA afin d’aider les experts en criminalistique numérique à identifier les images générées par l’IA. L’an dernier, les chercheurs ont publié une nouvelle méthode permettant d’appréhender les préjugés sociaux à l’aide de ChatGPT. Ils créent également des méthodes permettant d’identifier les avatars, un moyen de détecter si quelqu’un utilise la similarité, animée par l’IA, d’une autre personne sans son accord.
Pour protéger les données et les applications d’IA des menaces de sécurité, les GPU NVIDIA H100 et H200 Tensor Core sont bâtis sur l’informatique confidentielle qui garantit que les données sensibles sont protégées pendant leur utilisation, qu’elles soient déployées sur site, dans le cloud ou à l’edge. NVIDIA Confidential Computing utilise des méthodes de sécurité matérielles pour garantir que les entités non autorisées ne peuvent pas voir ou modifier les données ou les applications pendant leur exécution, le moment où elles sont généralement le plus vulnérable.
Transparence : rendre l’IA explicable
Pour créer un modèle d’IA fiable, l’algorithme ne peut pas être une boîte noire : ses créateurs, ses utilisateurs et ses parties prenantes doivent pouvoir comprendre comment fonctionne l’IA pour avoir confiance en ses résultats.
Dans le domaine de l’IA, la transparence est un ensemble de meilleures pratiques, d’outils et de principes de conception qui aident les utilisateurs et les autres parties prenantes à comprendre comment un modèle d’IA a été entraîné et comment il fonctionne. L’IA explicable, ou XAI, est un sous-ensemble de la transparence couvrant les outils qui informent les parties prenantes sur la façon dont un modèle d’IA fait certaines prédictions et prend certaines décisions.
La transparence et l’XAI sont essentielles pour que les systèmes d’IA inspirent confiance, mais il n’existe pas de solution universelle adaptable à tous les types de modèle d’IA et de parties prenantes. Pour trouver la bonne solution, une approche systémique doit être employée pour identifier les individus que l’IA affecte, analyser les risques associés et mettre en œuvre des mécanismes efficaces pour fournir des informations sur le système d’IA.
La génération augmentée par récupération, ou RAG, est une technique qui fait progresser la transparence de l’IA en connectant des services d’IA générative à des bases de données externes faisant autorité, ce qui permet aux modèles de citer leurs sources et de fournir des réponses plus précises. NVIDIA aide les développeurs à démarrer avec un workflow RAG qui utilise le framework NVIDIA NeMo pour développer et personnaliser des modèles d’IA générative.
NVIDIA est également membre de l’U.S. Artificial Intelligence Safety Institute Consortium, ou AISIC, du National Institute of Standards and Technology qui vise à créer des outils et des normes pour le développement et le déploiement responsables de l’IA. En tant que membre du consortium, NVIDIA pourra promouvoir l’IA fiable en tirant parti des meilleures pratiques pour mettre en œuvre la transparence des modèles d’IA.
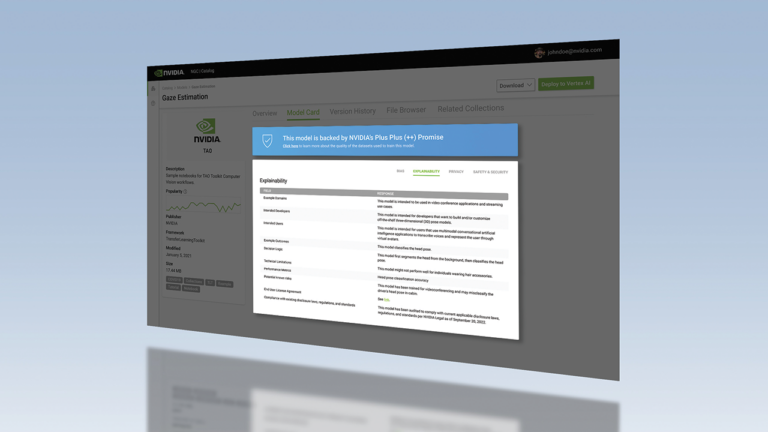
Sur le hub de NVIDIA dédié aux logiciels accélérés, NGC, des cartes de modèles offrent des informations détaillées sur la façon dont chaque modèle d’IA fonctionne et a été conçu. Le format ++ des cartes de modèles de NVIDIA décrit les ensembles de données, les méthodes d’entraînement et les mesures de performances utilisées, des informations sur les licences, ainsi que des considérations spécifiques sur l’éthique.
Non-discrimination : minimiser les préjugés
Les modèles d’IA sont entraînés par des êtres humains, souvent à l’aide de données dont la taille, la portée et la diversité sont limitées. Pour s’assurer que toutes les personnes et communautés ont la possibilité de bénéficier de cette technologie, il est important de lutter contre les préjugés dans les systèmes d’IA.
Au-delà du respect des directives gouvernementales et des lois anti-discrimination, les développeurs d’IA fiable réduisent les préjugés potentiels en recherchant des indices et des modèles qui suggèrent qu’un algorithme est discriminatoire ou utilise certaines caractéristiques de manière inappropriée. Les préjugés raciaux et sexistes sont notoires dans les données, mais d’autres facteurs comprennent des préjugés culturels et des préjugés introduits lors de l’étiquetage des données. Pour réduire les préjugés indésirables, les développeurs peuvent intégrer différentes variables dans leurs modèles.
Les ensembles de données synthétiques offrent une solution qui permet de réduire les préjugés indésirables dans les données d’entraînement utilisées pour développer l’IA destinée aux véhicules autonomes et à la robotique. Si les données utilisées pour entraîner des voitures autonomes sous-représentent des situations inhabituelles comme des conditions météorologiques extrêmes ou des accidents de la route, les données synthétiques peuvent contribuer à accroître la diversité de ces ensembles de données pour mieux représenter le monde réel, ce qui aide à améliorer la précision de l’IA.
NVIDIA Omniverse Replicator, un framework basé sur la plateforme NVIDIA Omniverse pour créer et exploiter des pipelines 3D et des mondes virtuels, aide les développeurs à mettre en place des pipelines personnalisés pour la génération de données synthétiques. Et en intégrant le kit d’outils NVIDIA TAO pour l’apprentissage par transfert avec Innotescus, une plateforme web qui permet d’organiser des ensembles de données exempts de préjugés destinés à la vision par ordinateur, les développeurs peuvent mieux comprendre les schémas des ensembles de données et les préjugés afin de résoudre les déséquilibres statistiques.
Vous trouverez davantage d’informations sur l’IA fiable sur NVIDIA.com et le blog NVIDIA. Pour en savoir plus sur la façon de s’attaquer aux préjugés indésirables dans l’IA, regardez cette présentation de la NVIDIA GTC et assistez à la session sur l’IA fiable lors de la prochaine conférence, qui se tiendra du 18 au 21 mars à San Jose, en Californie, et en ligne.